
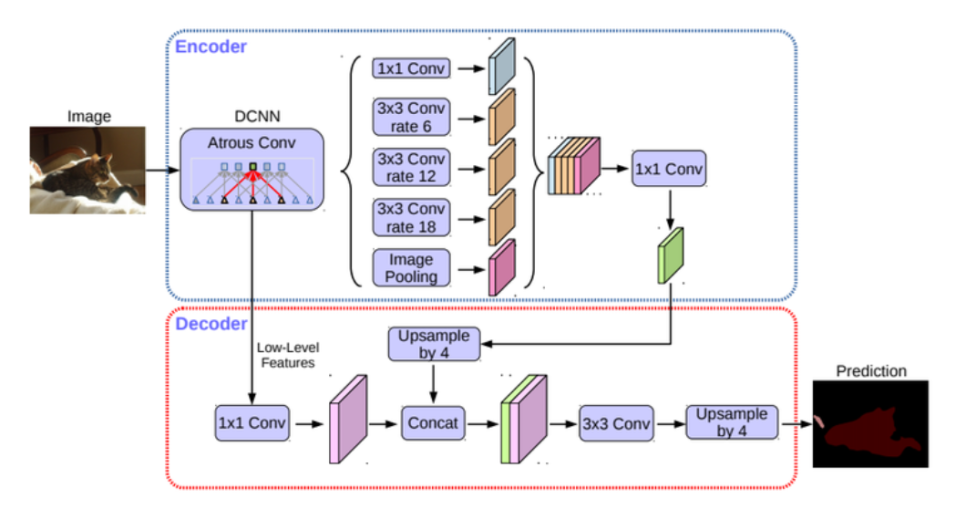
DeepLabv3+
- U-Net에서의 Contracting path과 Expansive path의 역할을 하는 것이 여기서는 인코더, 디코더임.
- 인코더: 이미지에서 필요한 정보를 특성으로 추출해 내는 모듈
- 디코더: 추출된 특성을 이용해 원하는 정보를 예측하는 모듈
- ASPP(Atrous Spatial Pyramid Pooling)가 있는 블록을 통해 특성을 추출하고, 디코더에서 Upsampling을 통해 세그멘테이션 마스크를 얻음.
Atrous Convolution
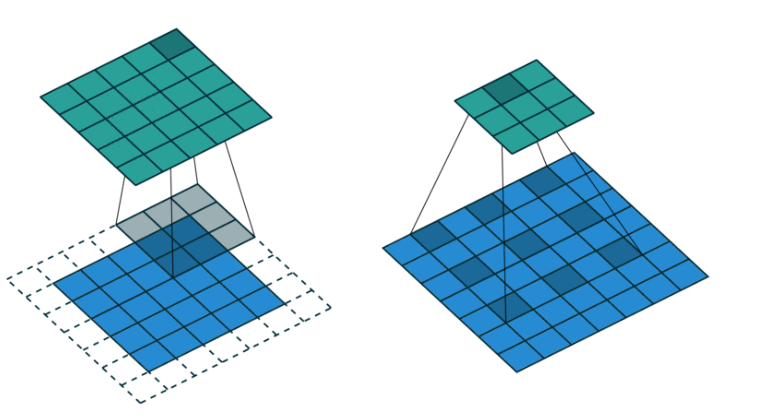
- 일반적인 컨볼루션과 달리 더 넓은 영역을 보도록 해주기 위한 방법으로, 커널이 일정 간격으로 떨어져 있음.
- 컨볼루션 레이어를 너무 깊게 쌓지 않아도 넓은 영역의 정보를 커버할 수 있게됨.
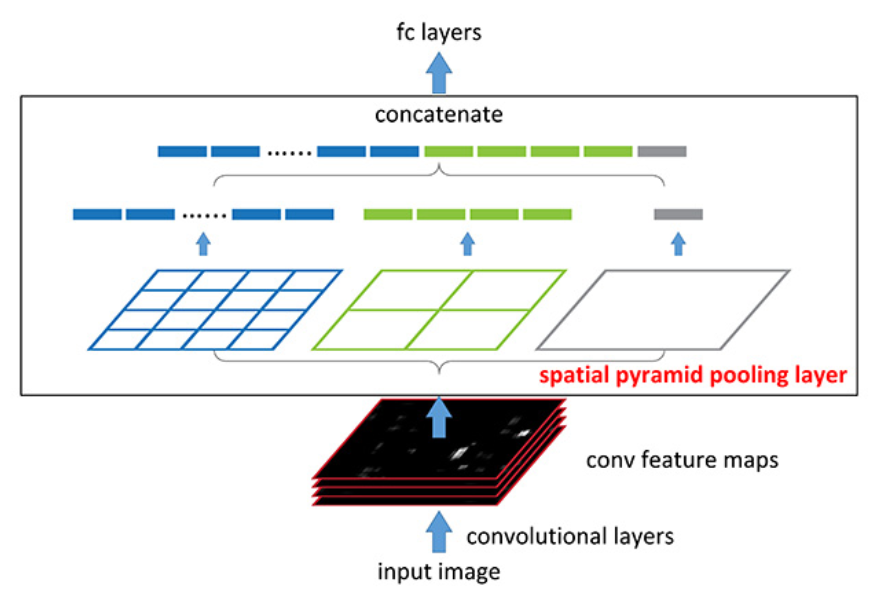
Spatial Pyramid Pooling
- 여러 가지 스케일로 convolution과 pooling을 하고 나온 다양한 특성을 연결(concatenate)해줌.
- 멀티스케일로 특성을 추출하는 것을 병렬로 수행하는 효과를 얻을 수 있음.
- 입력 이미지의 크기와 관계없이 동일한 구조를 활용할 수 있다는 장점이 있음.
- 제각기 다양한 크기와 비율을 가진 RoI 영역에 대해 적용하기에 유리함.
Pixel Accuracy
- 픽셀에 따른 정확도
- 예측 결과 맵(prediction map)을 클래스 별로 평가하는 경우에는 이진 분류 문제로 생각해 픽셀 및 채널 별로 평가함.
- 픽셀 별 이미지 분류 문제로 평가하는 경우에는 픽셀 별로 정답 클래스를 맞추었는지 여부, 즉 True/False를 구분함.
Mask IoU
- 정답 라벨(ground truth)과 예측결과 바운딩 박스(prediction bounding box) 사이의 IoU(intersection over union)를 사용함.
- 마스크 IoU를 클래스 별로 계산하면 한 이미지에서 여러 클래스에 대한 IoU 점수를 얻을 수 있으며, 이를 평균하면 전체적인 시맨틱 세그멘테이션 성능을 가늠할 수 있음.
intersection = np.logical_and( target, prediction )
union = np.logical_or( target, prediction )
iou_score = np.sum( intersection ) / np.sum( union )
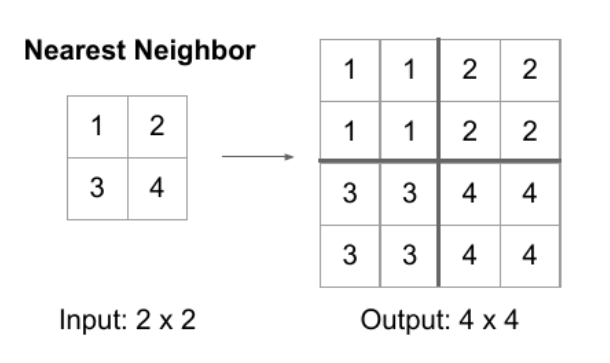
Nearest Neighbor
- scale을 키운 위치에서 원본에서 가장 가까운 값을 그대로 적용하는 방법
Bilinear Interpolation
- 두 축에 대해 선형보간법을 통해 필요한 값을 메우는 방식
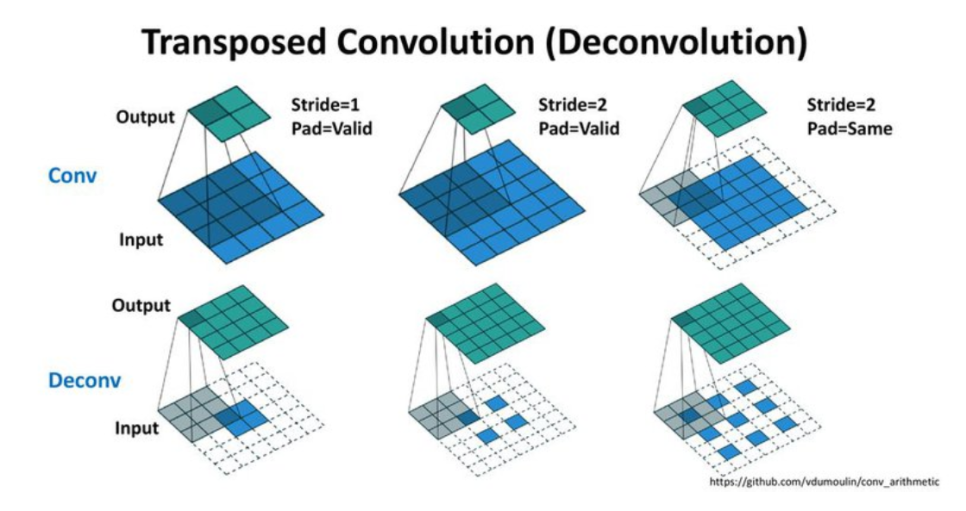
Transposed Convolution
- 학습할 수 있는 파라미터를 가진 Upsampling 방법
- 거꾸로 학습된 파라미터로 입력된 벡터를 통해 더 넓은 영역의 값을 추정해냄.
이미지 분류 문제 (Image Classification)
- 이미지의 local feature를 추출하기 위해 CNN으로 구성된 특성 추출용 백본 네트워크(backbone network)가 앞에 있음.
- 백본 네트워크에서 추출된 특성 맵을 fully connected layer에 통과시켜 얻어진 logit을 소프트맥스 활성화 함수에 통과시키면, 입력 이미지가 각 클래스에 속할 확률을 얻을 수 있음.
- 모델 내부에서 정답의 이유를 찾아볼 수 있는 방법으로는 레이어마다 feature map을 시각화해서, activation이 어떻게 되어있는지 확인하는 것이 있음.
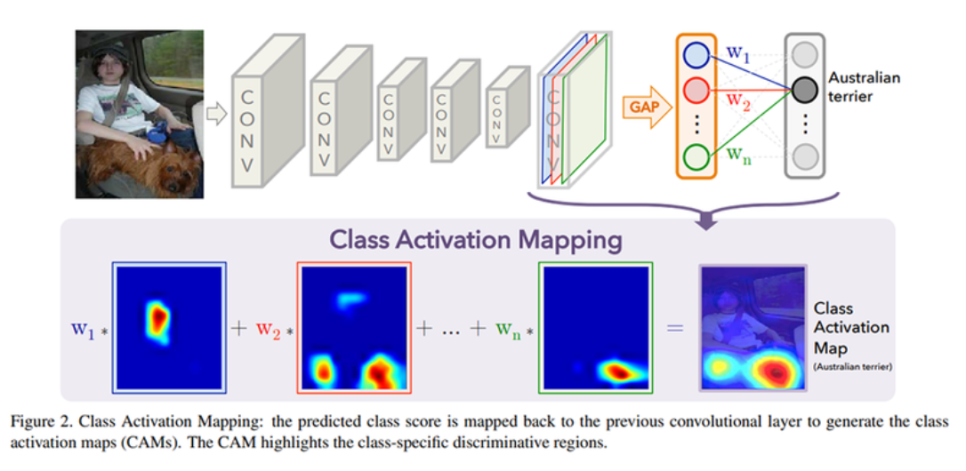
CAM (Class Activation Map)
- 모델이 어떤 곳을 보고 어떤 클래스임을 짐작하고 있는지 확인할 수 있는 지도
- 클래스가 활성화되는 지도
- 클래스별로 소프트맥스 레이어를 통해 각 채널의 가중합을 구하면 각 클래스가 활성화 맵의 어떤 부분을 주로 활성화시키는지 확인할 수 있음.
- Mc(x,y)은 모델이 클래스c에 대해 각 위치를 얼마나 보고 있는지 나타내는 것
GAP (Global Average Pooling)
- 매 채널별로 average pooling을 채널의 값 전체에 global하게 적용함.
- 결과 벡터의 각 차원의 값은 특성 맵을 채널별로 평균낸 값임.
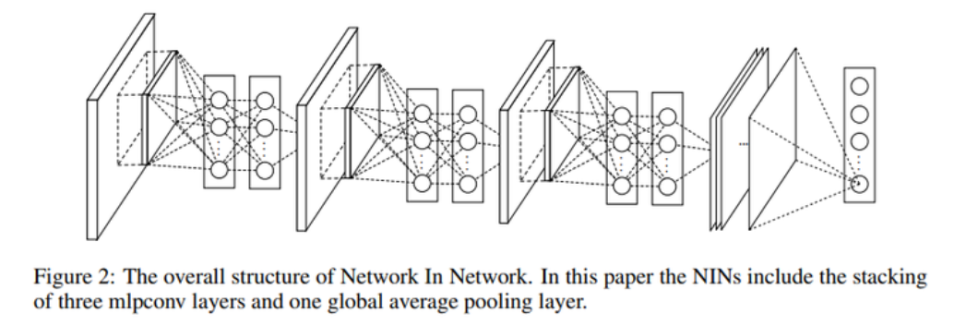
NIN (Network In Network)
- CNN 이후 fully connected layer 대신 GAP 연산을 하고, 그 연산 결과에 소프트맥스 활성화 함수를 적용함.
- 마지막 CNN 레이어의 채널 수는 데이터의 클래스 수에 맞춰 각 클래스에 따른 확률을 얻을 수 있도록 함.
- 특성 맵의 각 채널이 클래스별 신뢰도를 나타내게 되어 해석이 쉬움.
- 최적화할 파라미터가 존재하지 않아 과적합(overfitting)을 방지함.
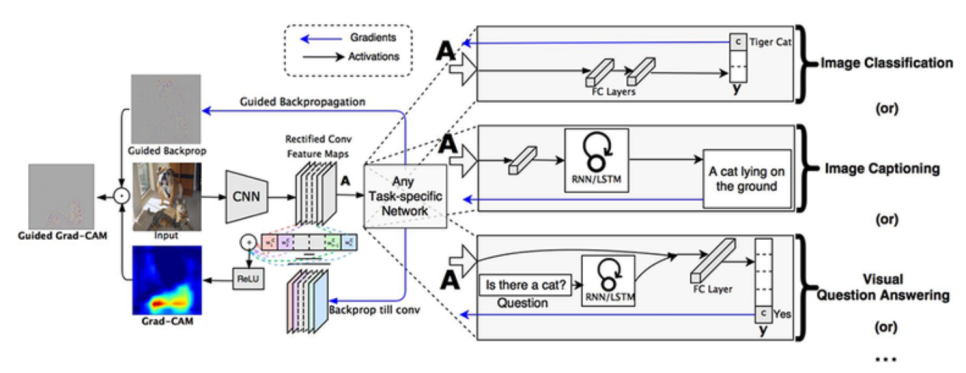
Grad-CAM (Gradient CAM)
- CAM 모델의 구조가 제한되는 문제를 해결하고, 다양한 모델의 구조를 해석할 수 있는 방법을 제안함.
- 굳이 모델 구조를 변경할 필요가 없으며, 분류 문제 외의 다른 태스크들에 유연하게 대처할 수 있음.
- Image Classification, Image captioning, Visual question Answering 등에 Grad-CAM이 적용될 수 있음.
- Image Captioning: 이미지에 대한 설명을 만들어내는 태스크
- Visual question answering: VQA라고도 불리며, 어떤 질문과 이미지가 주어졌을 때 이에 대한 답변을 내는 태스크
- 그래디언트를 통해 Weight Score를 계산함.
- k번째 활성화 맵과 이 가중치를 곱해주어 합한 뒤, ReLU 활성화 함수를 통해서 클래스에 따른 Grad-CAM을 얻음.
- ReLU를 사용함으로써 활성화된 영역을 확인해야하기 때문에 불필요한 음의 값을 줄여줄 수 있음.
- 가중치 점수를 제거했을 때 prediction이 바뀌도록 하는 가중치 영역을 모으면 bounding box 라벨을 한번도 보지 않고서도 object detection을 해낼 수 있음.
- Grad-CAM을 이용해서 Semantic Segmentation도 수행 가능함.
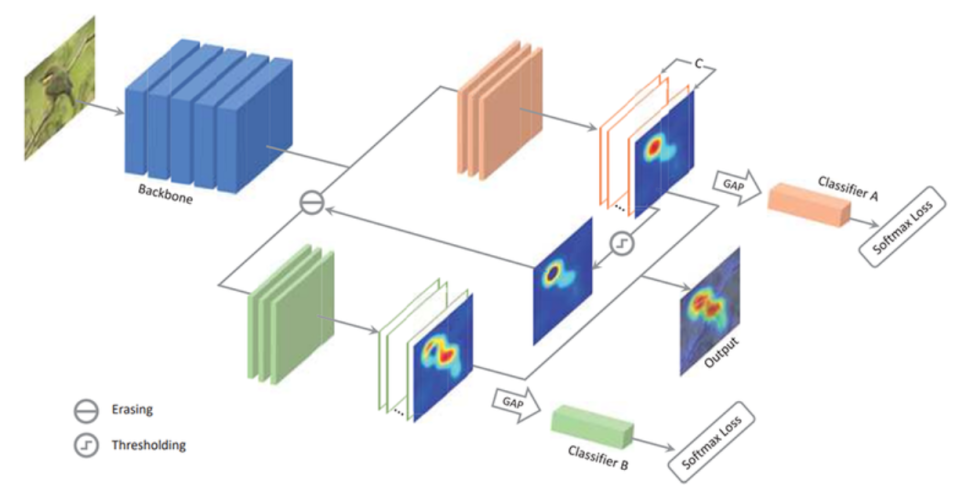
ACoL (Adversarial Complementary Learning)
- CAM 모델이 특정 부위에 집중해 학습하는 것을 막기 위해 브랜치를 두 가지로 두어 너무 높은 점수를 지워줌으로써 주변의 특성 또한 반영함.
- 물체의 전반적인 영역으로 CAM이 활성화되는 효과
- 커널 사이즈는 1x1, 출력 채널의 개수는 분류하고자 하는 클래스 개수를 가진 컨볼루션 레이어를 특성 맵에 사용하고 여기에 GAP를 적용함.
- 여기서 컨볼루션 레이어의 출력값은 곧바로 활성화 맵이 됨.
약지도학습 (weakly supervised learning)
- 직접적으로 정답 위치정보를 주지 않아도, 간접적인 정보를 활용하여 학습하고 원하는 정보를 얻어낼 수 있도록 모델을 학습하는 방식
- CAM, Grad-CAM, ACoL 등의 모델이 있음.
- incomplete supervision: 학습 데이터 중 일부에만 라벨이 달린 경우
- inexact supervision: 학습데이터의 라벨이 충분히 정확하게 달려있지 않은 경우
- inaccurate supervision: 학습 데이터에 Noise가 있는 경우



