OCR (Optical Character Recognition)
- 스캐너를 통해 입력된 문서 영상에서 문자에 해당하는 부분의 내용을 인식하는 기술
- 문자의 존재를 Detection 하고 나서, 어떤 문자인지 판독하는 Recognition의 과정을 거침.
Detection: 입력받은 사진 속에서 문자의 위치를 찾아냄.
↓
Recognition: 찾은 문자 영역으로부터 문자를 읽어냄.

객체 탐지 (Object Detection)를 통한 문자 인식
- 이미지 속에서 '물체'를 찾아내는 딥러닝 모델에게 '문자'를 찾도록 학습을 시킴.
- 문자의 특성에 따라서 모델을 변경해 주기도 함.
- Regression 방식: 이미지 -> CNN -> 글자영역 표현값 / 기준으로 하는 박스 대비 문자의 박스가 얼마나 차이 나
는지를 학습함. / RECT 표현법이 다수임. / 성능 재현이 어려움.
- Segmentation 방식: 이미지 -> CNN -> 픽셀단위 정보 -> 간단한 규칙 -> 글자영역 표현값 / 픽셀 단위로 해당
픽셀이 문자를 표현하는지를 분류함. / RBOX 표현법이 다수임. / 학습이 안정적임.
- end-to-end 방식: detection과 recognition을 한번에 학습시켜 상호 도움이 되도록 함.

Google Cloud Vision API
def detect_text( path ):
from google.cloud import vision
client = vision.ImageAnnotatorClient( )
with io.open( path, 'rb' ) as image_file:
content = image_file.read( )
image = vision.Image( content = content )
response = client.text_detection( image=image )
texts = response.text_annotations
print('Texts:')
for text in texts:
print('\n"{}"'.format( text.description ))
vertices = (['({},{})'.format( vertex.x, vertex.y )
for vertex in text.bounding_poly.vertices])
print('bounds: {}'.format(','.join(vertices)))
# 다운받은 인증키 경로
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=os.getenv('HOME')+'/aiffel/ocr_python/my_google_api_key.json'
# 입력 이미지 경로
path = os.getenv('HOME') + '/aiffel/ocr_python/OCR_test_image.jpg'
# 위에서 정의한 OCR API 이용 함수를 호출
detect_text( path )
keras-ocr
import keras_ocr
pipeline = keras_ocr.pipeline.Pipeline( ) # 초기화 과정에서 미리 학습된 모델의 가중치를 불러옴.
image_urls = [
'https://source.unsplash.com/M7mu6jXlcns/640x460',
'https://source.unsplash.com/6jsp4iHc8hI/640x460',
'https://source.unsplash.com/98uYQ-KupiE',
]
images = [ keras_ocr.tools.read(url) for url in image_urls ]
prediction_groups = [ pipeline.recognize([url]) for url in image_urls ]
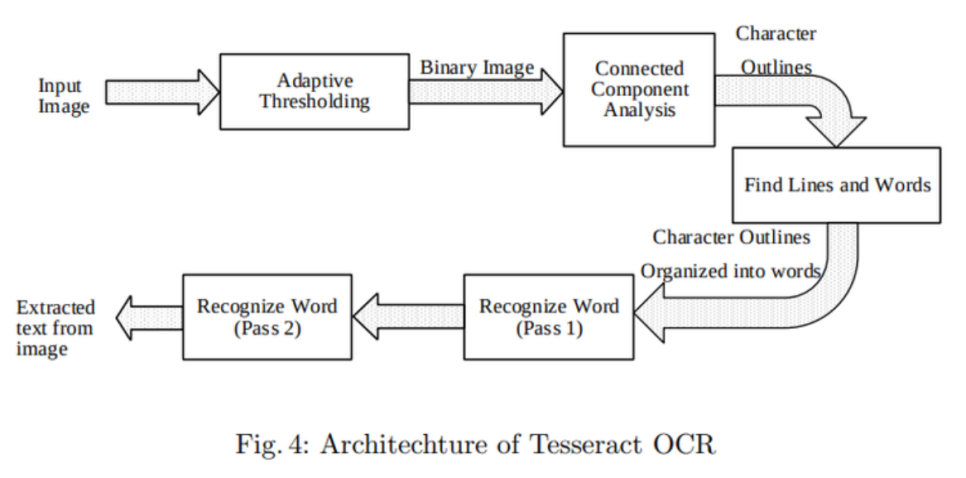
Tesseract
구글의 후원을 받는 오픈소스 OCR 엔진
1. Adaptive Thresholding 단계에서 입력 영상의 이진화를 통해 흑백으로 변환
2. Connected Component Analysis 단계에서 문자 영역을 검출
3. Find Lines and Words에서 라인 또는 단어 단위를 추출
4. Recognize Word 단계에서 단어 단위 이미지를 Text로 변환하기 위해 문자를 하나씩 인식하고 다시 결합
# Pytesseract: OS에 설치된 테서랙트를 파이썬에서 쉽게 사용할 수 있도록 해주는 래퍼 라이브러리
import pytesseract
from pytesseract import Output
# 테스트 이미지를 받아서 문자 검출을 진행한 후, crop한 이미지 파일들로 리턴하는 함수
def crop_word_regions( image_path='./images/sample.png', output_path='./output' ):
custom_oem_psm_config = r'--oem 3 --psm 3'
image = Image.open( image_path )
recognized_data = pytesseract.image_to_data( image, lang = 'kor',
config = custom_oem_psm_config,
output_type = Output.DICT )
top_level = max( recognized_data['level'] )
index = 0
cropped_image_path_list = [ ]
for i in range( len( recognized_data['level'] ) ):
level = recognized_data['level'][i]
if level == top_level:
left = recognized_data['left'][i]
top = recognized_data['top'][i]
width = recognized_data['width'][i]
height = recognized_data['height'][i]
output_img_path = os.path.join( output_path, f"{str(index).zfill(4)}.png" )
print( output_img_path )
cropped_image = image.crop(( left , top , left+width , top+height ))
cropped_image.save( output_img_path )
cropped_image_path_list.append( output_img_path )
index += 1
return cropped_image_path_list
work_dir = os.getenv('HOME') + '/aiffel/ocr_python'
img_file_path = work_dir + '/test_image.png' # 테스트용 이미지 경로
cropped_image_path_list = crop_word_regions( img_file_path, work_dir )
# 이미지에서 단어를 인식하는 함수
def recognize_images( cropped_image_path_list ):
custom_oem_psm_config = r'--oem 3 --psm 7'
# image_to_string(): 검출된 바운딩 박스 이미지를 넣어주면 결과값으로 영역별 텍스트 문자가 나옴.
for image_path in cropped_image_path_list:
image = Image.open( image_path )
recognized_data = pytesseract.image_to_string( image, lang = 'kor',
config = custom_oem_psm_config,
output_type = Output.DICT )
recognize_images( cropped_image_path_list )
Text detection
- 일반적인 Object detection을 문자 찾아내기로 확장한 버전
- Object detection 기법뿐 아니라 Segmentation 기법도 동원
- 문자는 몇 개가 모여서 단어 혹은 문장을 이루고 있어서 이미지 내에서 문자를 검출해낼 때엔 '검출하기 위한 최소 단위'를 정해야 함.
- 문장 또는 단어 단위로 찾아낼 경우, 엄청나게 긴 단어나 문장과 함께 짧은 길이도 찾아낼 수 있도록 해야 함.
- 글자 단위로 찾아낼 경우, 글자를 다시 맥락에 맞게 묶어주는 과정을 거쳐야 함.
단어 단위의 탐지
- Regression기반의 Detection 방법
- Anchor를 정의하고 단어의 유무와 Bounding box의 크기를 추정해서 단어를 찾아냄.
- TextBoxes 모델이 있음.
글자 단위의 탐지
- 글자 영역을 Segmentation하는 방법으로 접근
- PixelLink 모델이 있음.
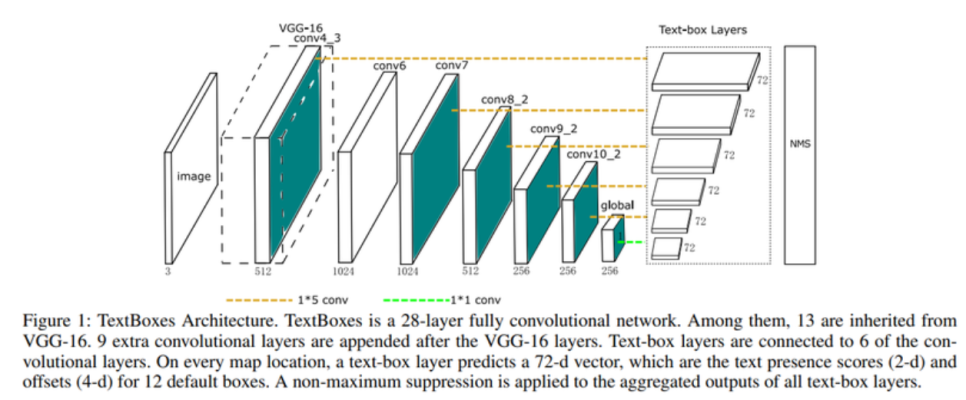
TextBoxes 모델
- 딥러닝 기반의 Detection을 이용하여 단어 단위로 인식함.
- 네트워크의 기본 구조는 SSD(single shot multibox detector)를 활용함.
- 가로로 긴 (Aspect ratio가 큰) 단어의 Feature를 활용하기 위해서 1x5로 convolution filter를 정의하여 사용함.
- Anchor box의 aspect ratio를 1, 2, 3, 5, 7로 만들고, 이에 vertical offset을 적용하여 세로 방향으로 촘촘한 단어의 배열에 대응하도록 함.
* 종횡비(Aspect ratio)
- 가로와 세로 길이의 비율
- 가로:세로의 형태로 표현함.
* offset
- 특정한 값에서 차이가 나는 값 또는 차이
- 차이가 목적에 의해 만들어진 것과 상황에 따라 자연스럽게 발생된 것을 모두 포함함.

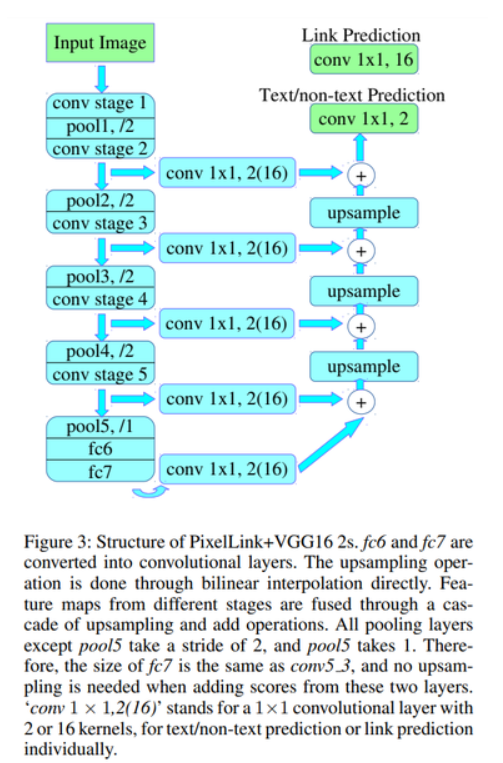
PixelLink 모델
- Text 영역을 찾아내는 segmentation과 함께, 글자가 어느 방향으로 link되는지를 같이 학습하여 Text 영역 간의 분리 및 연결을 할 수 있는 정보를 추가적으로 활용함.
- Text/non-text Prediction을 위한 class segmentation map으로 해당 영역이 Text인지 Non-text인지 예측값을 의미하는 2개의 커널을 가짐.
- conv 1X1, 2(16) 형태의 레이어가 U-Net 구조로 연결되어, 인접 pixel간 연결 구조가 지속적으로 유지되도록 하는 모델 구조
- 인접한 pixel이 중심 pixel과 단어 단위로 연결된 pixel인지 아니면 분리된 pixel인지 알 수 있으므로, 문자 영역이 단어 단위로 분리된 Instance segmentation이 가능해짐.

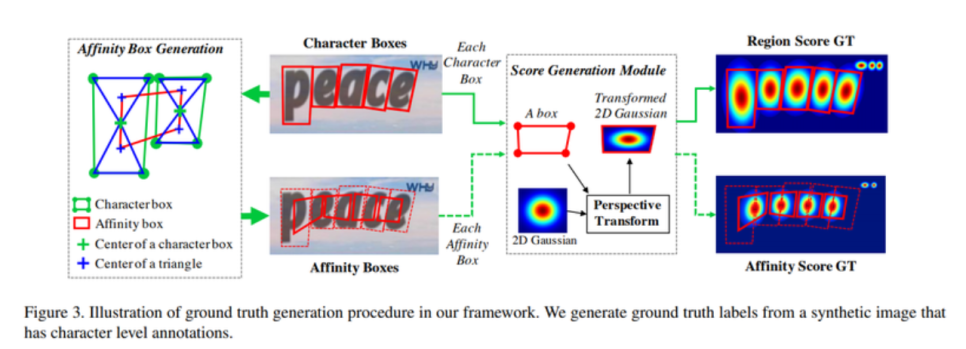
CRAFT (Character Region Awareness For Text Detection)
- 문자(Character) 단위로 문자의 위치를 찾아낸 뒤, 이를 연결하는 방식을 Segmentation 반으로 구현한 방법
- 문자의 영역을 boundary로 명확히 구분하지 않고, 가우시안 분포를 따르는 원형의 score map을 만들어서 배치시키는 방법
- 단어 단위의 정보만 있는 데이터셋에 대해 단어의 영역에 Inference를 한 후, 얻어진 문자 단위의 위치를 다시 학습에 활용하는 Weakly supervised learning을 활용함.
PMTD (Pyramid Mask Text Detector)
- Mask-RCNN의 구조를 활용하여 먼저 Text영역을 Region proposal network로 찾아냄.
- Box head에서 더 정확하게 regression 및 classification을 함.
- Mask head에서 Instance의 Segmentation을 하는 과정을 거침.
- Mask 정보가 부정확한 경우를 반영하기 위해서 Soft-segmentation을 활용함.
- 단어의 사각형 배치 특성을 반영하여 피라미드 형태의 Score map을 활용함.

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Text recognition
- 검출된 영역의 문자가 무엇인지를 인식해 내는 과정
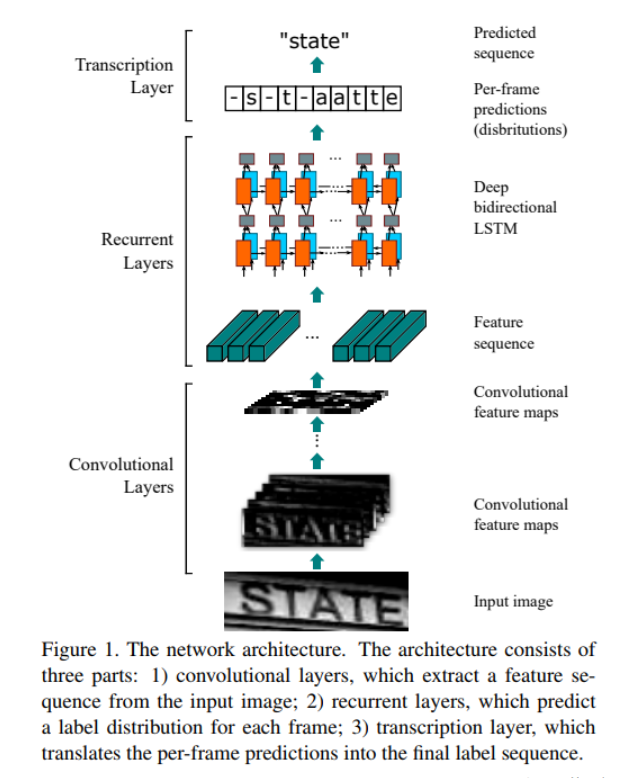
CRNN
- CNN과 RNN을 같이 쓰는 방법
- Step마다 Fully Connected Layer의 logit을 Softmax 함수에 넣어줌으로써 어떤 문자일 확률이 높은지 알 수 있음.
- Input과 Output이 서로 다른 길이의 Sequence를 가질 때, 이를 Align 없이 활용하는 방법인 CTC (Connectionist Temporal Classification)를 적용함.
- 실제 정답과 예측한 단어가 얼마나 가까운지 측정하기 위해 Edit distance를 사용함.
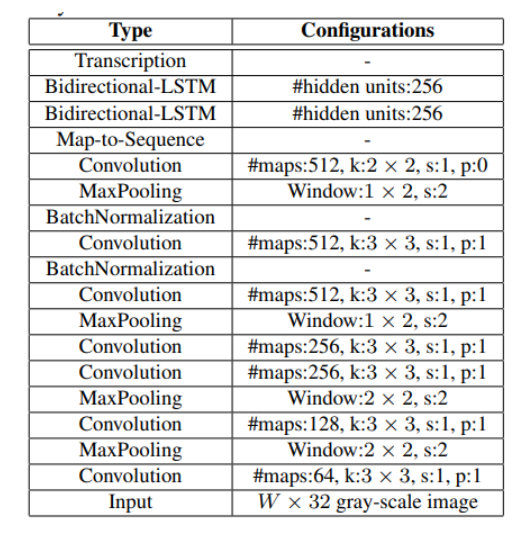
1. Feature Extractor로 사용되는 CNN 기반의 VGG 또는 ResNet과 같은 네트워크로부터 문자의 정보를 가진 Feature를 얻어냄.
2. 추출된 Feature를 Map-To-Sequence를 통해 Sequence 형태의 feature로 변환한 후, 다양한 길이의 Input을 처리할 수 있는 RNN으로 넣음.
3. Bidirectional LSTM을 사용해 step마다 나오는 결과를 Transcription Layer에서 문자로 변환함.
TPS (Thin Plate Spline)
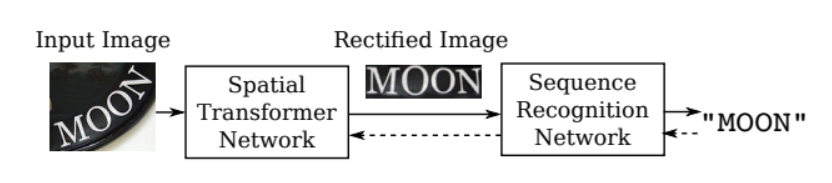
- 입력 이미지를 단어 영역에 맞게 변형시켜 인식이 잘되도록 해줌.
- control point를 정의하고 해당 point들이 특정 위치로 옮겨졌을 때, 축 방향의 변화를 interpolation하여 모든 위치의 변화를 추정해냄.
- 전체 이미지 pixel의 변화를 control point로 만들어냄.
- spatial Transformer Network를 통해서 Control point가 얼마나 움직여야 하는지 예측하는 네트워크를 Recognition model 앞단에 붙여 입력 이미지를 정방향으로 맞춰줌.
( * Spatial Transformer Network: 인풋 이미지에 크기, 위치, 회전 등의 변환을 가해 추론을 더욱 용이하게 하는 transform matrix를 찾아 매핑하는 네트워크 )
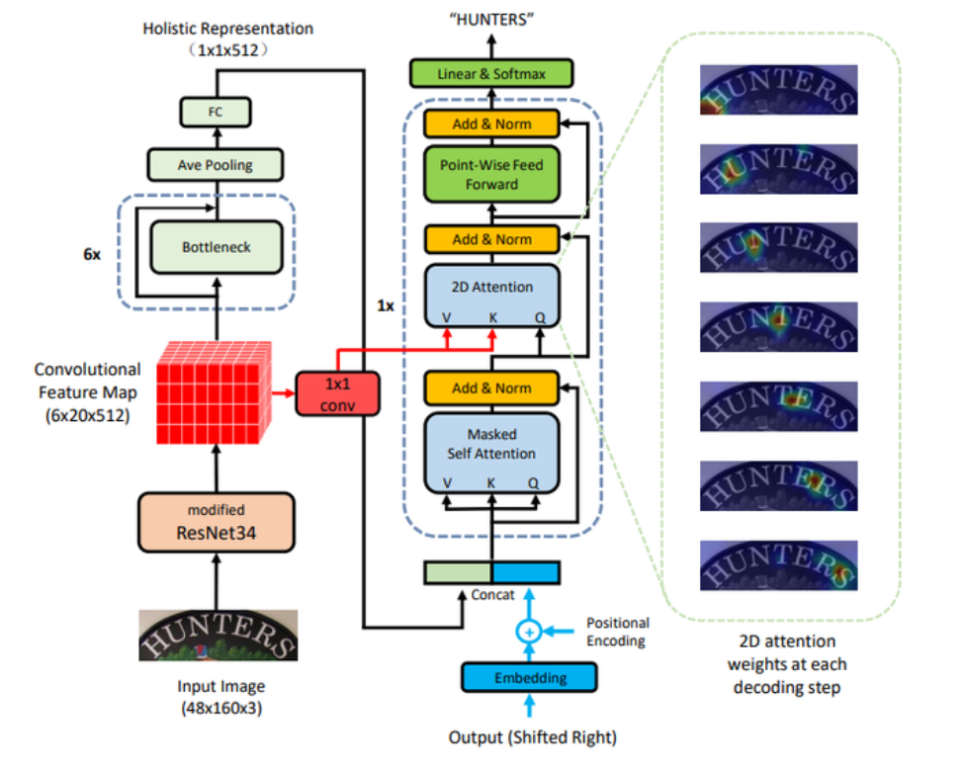
Attention과 Transformer
- 첫 번째 글자에서 입력 feature에 대한 Attention을 기반으로 label을 추정하고, 추정된 label을 다시 입력으로 사용하여 다음 글자를 추정해냄.
- Irregular text를 잘 인식하기 위해서 2d space에 대한 attention과 Transformer를 활용함.
- Transformer는 Query, Key, Value라는 개념을 통해서 Self-Attention을 입력으로부터 만들어냄. -> 입력에서 중요한 Feature에 대해 Weight를 줌.
- Decoder의 현재 포지션에서 중요한 Encoder의 State에 가중치가 높게 매겨짐.