
SSD (Single Shot MultiBox Detector)
- 다양한 크기의 feature map을 사용 -> 원본 이미지에서 grid 크기를 다르게 하는 효과
- convolution을 할 때 비율이 다른 default box를 설정
- 각 레이어에서 피쳐 맵들을 가져와 Object Detection을 수행한 결과들을 모두 합하여 localization loss와 confidence loss를 구한 다음, 전체 네트워크를 학습시키는 방식
- 학습 전에 ground truth와 defalt box의 jaccard overlap(IoU)이 0.5 이상인 것을 미리 매칭시켜 positive sample로 설정
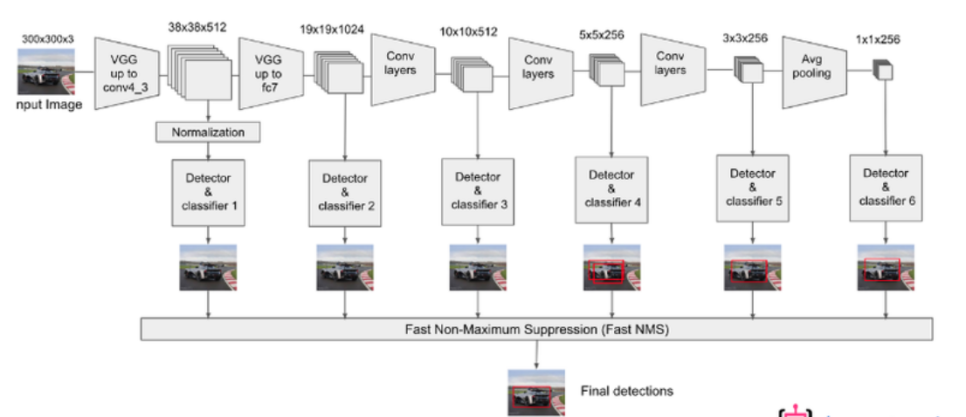

TinaFace
- 백본으로 ResNet50을 사용했고 기존에 존재했던 모듈(Feature Pyramid Network, Inception block, FCN 등)을 활용

RetinaFace
- 다양한 얼굴 크기에 대해 pixel-wise face localization을 수행
- 기존의 box classification과 regression 브랜치와 함께 extra-supervised and self-supervised multi-task learning을 수행

DSFD (Dual Shot Face Detector)
- Feature Enhance Module(FEM), Progressive Anchor Loss(PAL), Improved Anchor Matching (IAM)라는 기법을 사용해 성능을 높인 모델
S3FD
- 하나의 deep neural network를 사용해 다양한 얼굴 크기에 대해 face detection을 수행
- 다양한 크기의 얼굴을 잘 찾기 위해 layer의 넓은 범위에 anchor를 바둑판 형식으로 배열하였고, anchor 크기도 새롭게 디자인
-----------------------------------------------------------------
SSD 모델을 통한 Multi-face detector구현
import os, cv2, time
import tensorflow as tf
import tqdm
import numpy as np
import math
from itertools import product
import matplotlib.pyplot as plt
PROJECT_PATH = os.getenv('HOME')+'/aiffel/face_detector'
DATA_PATH = os.path.join(PROJECT_PATH, 'widerface')
MODEL_PATH = os.path.join(PROJECT_PATH, 'checkpoints')
TRAIN_TFRECORD_PATH = os.path.join(PROJECT_PATH, 'dataset', 'train_mask.tfrecord')
VALID_TFRECORD_PATH = os.path.join(PROJECT_PATH, 'dataset', 'val_mask.tfrecord')
CHECKPOINT_PATH = os.path.join(PROJECT_PATH, 'checkpoints')
DATASET_LEN = 12880
BATCH_SIZE = 32
IMAGE_WIDTH = 320
IMAGE_HEIGHT = 256
IMAGE_LABELS = ['background', 'face']
# bounding box 파일을 분석
def parse_box(data):
x0 = int(data[0])
y0 = int(data[1])
w = int(data[2])
h = int(data[3])
return x0, y0, w, h
# 이미지별 bounding box 정보를 wider_face_train_bbx_gt.txt에서 파싱해서 리스트로 추출
def parse_widerface(file):
infos = []
with open(file) as fp:
line = fp.readline()
while line:
n_object = int(fp.readline())
boxes = []
for i in range(n_object):
box = fp.readline().split(' ')
x0, y0, w, h = parse_box(box)
if (w == 0) or (h == 0):
continue
boxes.append([x0, y0, w, h])
if n_object == 0:
box = fp.readline().split(' ')
x0, y0, w, h = parse_box(box)
boxes.append([x0, y0, w, h])
infos.append((line.strip(), boxes))
line = fp.readline()
return infos
# bounding box 정보는 [x, y, w, h] 형태로 저장되어 있는데, [x_min, y_min, x_max, y_max] 형태의 꼭짓점 좌표 정보로 변환
def process_image(image_file):
image_string = tf.io.read_file(image_file)
try:
image_data = tf.image.decode_jpeg(image_string, channels=3)
return 0, image_string, image_data
except tf.errors.InvalidArgumentError:
return 1, image_string, None
def xywh_to_voc(file_name, boxes, image_data):
shape = image_data.shape
image_info = {}
image_info['filename'] = file_name
image_info['width'] = shape[1]
image_info['height'] = shape[0]
image_info['depth'] = 3
difficult = []
classes = []
xmin, ymin, xmax, ymax = [], [], [], []
for box in boxes:
classes.append(1)
difficult.append(0)
xmin.append(box[0])
ymin.append(box[1])
xmax.append(box[0] + box[2])
ymax.append(box[1] + box[3])
image_info['class'] = classes
image_info['xmin'] = xmin
image_info['ymin'] = ymin
image_info['xmax'] = xmax
image_info['ymax'] = ymax
image_info['difficult'] = difficult
return image_info
# tf.train.Example 인스턴스를 생성하는 메소드
def make_example(image_string, image_infos):
for info in image_infos:
filename = info['filename']
width = info['width']
height = info['height']
depth = info['depth']
classes = info['class']
xmin = info['xmin']
ymin = info['ymin']
xmax = info['xmax']
ymax = info['ymax']
if isinstance(image_string, type(tf.constant(0))):
encoded_image = [image_string.numpy()]
else:
encoded_image = [image_string]
base_name = [tf.compat.as_bytes(os.path.basename(filename))]
example = tf.train.Example(features=tf.train.Features(feature={
'filename':tf.train.Feature(bytes_list=tf.train.BytesList(value=base_name)),
'height':tf.train.Feature(int64_list=tf.train.Int64List(value=[height])),
'width':tf.train.Feature(int64_list=tf.train.Int64List(value=[width])),
'classes':tf.train.Feature(int64_list=tf.train.Int64List(value=classes)),
'x_mins':tf.train.Feature(float_list=tf.train.FloatList(value=xmin)),
'y_mins':tf.train.Feature(float_list=tf.train.FloatList(value=ymin)),
'x_maxes':tf.train.Feature(float_list=tf.train.FloatList(value=xmax)),
'y_maxes':tf.train.Feature(float_list=tf.train.FloatList(value=ymax)),
'image_raw':tf.train.Feature(bytes_list=tf.train.BytesList(value=encoded_image))
}))
return example
# example을 serialize하여 TFRecord 파일로 생성
for split in ['train', 'val']:
if split == 'train':
output_file = TRAIN_TFRECORD_PATH
anno_txt = 'wider_face_train_bbx_gt.txt'
file_path = 'WIDER_train'
else:
output_file = VALID_TFRECORD_PATH
anno_txt = 'wider_face_val_bbx_gt.txt'
file_path = 'WIDER_val'
with tf.io.TFRecordWriter(output_file) as writer:
for info in tqdm.tqdm(parse_widerface(os.path.join(DATA_PATH, 'wider_face_split', anno_txt))):
image_file = os.path.join(DATA_PATH, file_path, 'images', info[0])
error, image_string, image_data = process_image(image_file)
boxes = xywh_to_voc(image_file, info[1], image_data)
if not error:
tf_example = make_example(image_string, [boxes])
writer.write(tf_example.SerializeToString())
# default box 정보를 전역 변수로 만들어둠.
BOX_MIN_SIZES = [[10, 16, 24], [32, 48], [64, 96], [128, 192, 256]]
BOX_STEPS = [8, 16, 32, 64]
# 4가지 유형의 feature map을 생성
image_sizes = (IMAGE_HEIGHT, IMAGE_WIDTH)
min_sizes = BOX_MIN_SIZES
steps= BOX_STEPS
feature_maps = [
[math.ceil(image_sizes[0] / step), math.ceil(image_sizes[1] / step)]
for step in steps
]
feature_maps
# feature map별로 순회하면서 default box를 생성
boxes = []
for k, f in enumerate(feature_maps):
for i, j in product(range(f[0]), range(f[1])):
for min_size in min_sizes[k]:
s_kx = min_size / image_sizes[1]
s_ky = min_size / image_sizes[0]
cx = (j + 0.5) * steps[k] / image_sizes[1]
cy = (i + 0.5) * steps[k] / image_sizes[0]
boxes += [cx, cy, s_kx, s_ky]
len(boxes)
pretty_boxes = np.asarray(boxes).reshape([-1, 4])
print(pretty_boxes.shape)
print(pretty_boxes)
# feature map을 만들고 그에 연결된 default box를 생성
def default_box():
image_sizes = (IMAGE_HEIGHT, IMAGE_WIDTH)
min_sizes = BOX_MIN_SIZES
steps= BOX_STEPS
feature_maps = [
[math.ceil(image_sizes[0] / step), math.ceil(image_sizes[1] / step)]
for step in steps
]
boxes = []
for k, f in enumerate(feature_maps):
for i, j in product(range(f[0]), range(f[1])):
for min_size in min_sizes[k]:
s_kx = min_size / image_sizes[1]
s_ky = min_size / image_sizes[0]
cx = (j + 0.5) * steps[k] / image_sizes[1]
cy = (i + 0.5) * steps[k] / image_sizes[0]
boxes += [cx, cy, s_kx, s_ky]
boxes = np.asarray(boxes).reshape([-1, 4])
return boxes
# SSD model 빌드하기
def _conv_block(inputs, filters, kernel=(3, 3), strides=(1, 1)):
block_id = (tf.keras.backend.get_uid())
if strides == (2, 2):
x = tf.keras.layers.ZeroPadding2D(padding=((1, 1), (1, 1)), name='conv_pad_%d' % block_id)(inputs)
x = tf.keras.layers.Conv2D(filters, kernel,
padding='valid',
use_bias=False,
strides=strides,
name='conv_%d' % block_id)(x)
else:
x = tf.keras.layers.Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv_%d' % block_id)(inputs)
x = tf.keras.layers.BatchNormalization(name='conv_bn_%d' % block_id)(x)
return tf.keras.layers.ReLU(name='conv_relu_%d' % block_id)(x)
def _depthwise_conv_block(inputs, filters, strides=(1, 1)):
block_id = tf.keras.backend.get_uid()
if strides == (1, 1):
x = inputs
else:
x = tf.keras.layers.ZeroPadding2D(((1, 1), (1, 1)), name='conv_pad_%d' % block_id)(inputs)
x = tf.keras.layers.DepthwiseConv2D((3, 3),
padding='same' if strides == (1, 1) else 'valid',
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(x)
x = tf.keras.layers.BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = tf.keras.layers.ReLU(name='conv_dw_%d_relu' % block_id)(x)
x = tf.keras.layers.Conv2D(filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = tf.keras.layers.BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return tf.keras.layers.ReLU(name='conv_pw_%d_relu' % block_id)(x)
def _branch_block(inputs, filters):
x = tf.keras.layers.Conv2D(filters, kernel_size=(3, 3), padding='same')(inputs)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Conv2D(filters, kernel_size=(3, 3), padding='same')(x)
x1 = tf.keras.layers.Conv2D(filters * 2, kernel_size=(3, 3), padding='same')(inputs)
x = tf.keras.layers.Concatenate(axis=-1)([x, x1])
return tf.keras.layers.ReLU()(x)
def _create_head_block(inputs, filters):
x = tf.keras.layers.Conv2D(filters, kernel_size=(3, 3), strides=(1, 1), padding='same')(inputs)
return x
def _compute_heads(inputs, num_class, num_cell):
conf = _create_head_block(inputs, num_cell * num_class)
conf = tf.keras.layers.Reshape((-1, num_class))(conf)
loc = _create_head_block(inputs, num_cell * 4)
loc = tf.keras.layers.Reshape((-1, 4))(loc)
return conf, loc
# SSD model 준비
def SsdModel():
base_channel = 16
num_cells = [3, 2, 2, 3]
num_class = len(IMAGE_LABELS)
x = inputs = tf.keras.layers.Input(shape=[IMAGE_HEIGHT, IMAGE_WIDTH, 3], name='input_image')
x = _conv_block(x, base_channel, strides=(2, 2))
x = _conv_block(x, base_channel * 2, strides=(1, 1))
x = _conv_block(x, base_channel * 2, strides=(2, 2))
x = _conv_block(x, base_channel * 2, strides=(1, 1))
x = _conv_block(x, base_channel * 4, strides=(2, 2))
x = _conv_block(x, base_channel * 4, strides=(1, 1))
x = _conv_block(x, base_channel * 4, strides=(1, 1))
x = _conv_block(x, base_channel * 4, strides=(1, 1))
x1 = _branch_block(x, base_channel)
x = _conv_block(x, base_channel * 8, strides=(2, 2))
x = _conv_block(x, base_channel * 8, strides=(1, 1))
x = _conv_block(x, base_channel * 8, strides=(1, 1))
x2 = _branch_block(x, base_channel)
x = _depthwise_conv_block(x, base_channel * 16, strides=(2, 2))
x = _depthwise_conv_block(x, base_channel * 16, strides=(1, 1))
x3 = _branch_block(x, base_channel)
x = _depthwise_conv_block(x, base_channel * 16, strides=(2, 2))
x4 = _branch_block(x, base_channel)
extra_layers = [x1, x2, x3, x4]
confs = []
locs = []
for layer, num_cell in zip(extra_layers, num_cells):
conf, loc = _compute_heads(layer, num_class, num_cell)
confs.append(conf)
locs.append(loc)
confs = tf.keras.layers.Concatenate(axis=1, name="face_classes")(confs)
locs = tf.keras.layers.Concatenate(axis=1, name="face_boxes")(locs)
predictions = tf.keras.layers.Concatenate(axis=2, name='predictions')([locs, confs])
model = tf.keras.Model(inputs=inputs, outputs=predictions, name='ssd_model')
return model
# 준비한 모델을 생성
model = SsdModel()
print("the number of model layers: ", len(model.layers))
model.summary()
# Default box 적용
def _intersect(box_a, box_b):
A = tf.shape(box_a)[0]
B = tf.shape(box_b)[0]
max_xy = tf.minimum(
tf.broadcast_to(tf.expand_dims(box_a[:, 2:], 1), [A, B, 2]),
tf.broadcast_to(tf.expand_dims(box_b[:, 2:], 0), [A, B, 2]))
min_xy = tf.maximum(
tf.broadcast_to(tf.expand_dims(box_a[:, :2], 1), [A, B, 2]),
tf.broadcast_to(tf.expand_dims(box_b[:, :2], 0), [A, B, 2]))
inter = tf.clip_by_value(max_xy - min_xy, 0.0, 512.0)
return inter[:, :, 0] * inter[:, :, 1]
def _jaccard(box_a, box_b):
inter = _intersect(box_a, box_b)
area_a = tf.broadcast_to(
tf.expand_dims(
(box_a[:, 2] - box_a[:, 0]) * (box_a[:, 3] - box_a[:, 1]), 1),
tf.shape(inter)) # [A,B]
area_b = tf.broadcast_to(
tf.expand_dims(
(box_b[:, 2] - box_b[:, 0]) * (box_b[:, 3] - box_b[:, 1]), 0),
tf.shape(inter)) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
# jaccard 메소드를 이용해 label의 ground truth bbox와 가장 overlap 비율이 높은 matched box를 구함.
# _encode_bbox 메소드를 통해 bbox의 scale을 동일하게 보정함.
# 전체 default box에 대해 일정 threshold 이상 overlap되는 ground truth bounding box 존재 여부(positive/negative)를 concat하여 새로운 label로 업데이트함.
def _encode_bbox(matched, boxes, variances=[0.1, 0.2]):
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - boxes[:, :2]
g_cxcy /= (variances[0] * boxes[:, 2:])
g_wh = (matched[:, 2:] - matched[:, :2]) / boxes[:, 2:]
g_wh = tf.math.log(g_wh) / variances[1]
g_wh = tf.where(tf.math.is_inf(g_wh), 0.0, g_wh)
return tf.concat([g_cxcy, g_wh], 1)
def encode_tf(labels, boxes):
match_threshold = 0.45
boxes = tf.cast(boxes, tf.float32)
bbox = labels[:, :4]
conf = labels[:, -1]
# jaccard index
overlaps = _jaccard(bbox, boxes)
best_box_overlap = tf.reduce_max(overlaps, 1)
best_box_idx = tf.argmax(overlaps, 1, tf.int32)
best_truth_overlap = tf.reduce_max(overlaps, 0)
best_truth_idx = tf.argmax(overlaps, 0, tf.int32)
best_truth_overlap = tf.tensor_scatter_nd_update(
best_truth_overlap, tf.expand_dims(best_box_idx, 1),
tf.ones_like(best_box_idx, tf.float32) * 2.)
best_truth_idx = tf.tensor_scatter_nd_update(
best_truth_idx, tf.expand_dims(best_box_idx, 1),
tf.range(tf.size(best_box_idx), dtype=tf.int32))
# Scale Ground-Truth Boxes
matches_bbox = tf.gather(bbox, best_truth_idx)
loc_t = _encode_bbox(matches_bbox, boxes)
conf_t = tf.gather(conf, best_truth_idx)
conf_t = tf.where(tf.less(best_truth_overlap, match_threshold), tf.zeros_like(conf_t), conf_t)
return tf.concat([loc_t, conf_t[..., tf.newaxis]], axis=1)
# augmemtation과 label을 encoding 하여 기존의 dataset을 변환
def _transform_data(train, boxes):
def transform_data(img, labels):
img = tf.cast(img, tf.float32)
if train:
img, labels = _crop(img, labels)
img = _pad_to_square(img)
img, labels = _resize(img, labels)
if train:
img, labels = _flip(img, labels)
if train:
img = _distort(img)
labels = encode_tf(labels, boxes)
img = img/255.0
return img, labels
return transform_data
# TFRecord 에 _transform_data를 적용하는 함수 클로저 생성
def _parse_tfrecord(train, boxes):
def parse_tfrecord(tfrecord):
features = {
'filename': tf.io.FixedLenFeature([], tf.string),
'height': tf.io.FixedLenFeature([], tf.int64),
'width': tf.io.FixedLenFeature([], tf.int64),
'classes': tf.io.VarLenFeature(tf.int64),
'x_mins': tf.io.VarLenFeature(tf.float32),
'y_mins': tf.io.VarLenFeature(tf.float32),
'x_maxes': tf.io.VarLenFeature(tf.float32),
'y_maxes': tf.io.VarLenFeature(tf.float32),
'difficult':tf.io.VarLenFeature(tf.int64),
'image_raw': tf.io.FixedLenFeature([], tf.string),
}
parsed_example = tf.io.parse_single_example(tfrecord, features)
img = tf.image.decode_jpeg(parsed_example['image_raw'], channels=3)
width = tf.cast(parsed_example['width'], tf.float32)
height = tf.cast(parsed_example['height'], tf.float32)
labels = tf.sparse.to_dense(parsed_example['classes'])
labels = tf.cast(labels, tf.float32)
labels = tf.stack(
[tf.sparse.to_dense(parsed_example['x_mins']),
tf.sparse.to_dense(parsed_example['y_mins']),
tf.sparse.to_dense(parsed_example['x_maxes']),
tf.sparse.to_dense(parsed_example['y_maxes']),labels], axis=1)
img, labels = _transform_data(train, boxes)(img, labels)
return img, labels
return parse_tfrecord
# tf.data.TFRecordDataset.map()에 _parse_tfrecord을 적용하는 실제 데이터셋 변환 메인 메소드
def load_tfrecord_dataset(tfrecord_name, train=True, boxes=None, buffer_size=1024):
raw_dataset = tf.data.TFRecordDataset(tfrecord_name)
raw_dataset = raw_dataset.cache()
if train:
raw_dataset = raw_dataset.repeat()
raw_dataset = raw_dataset.shuffle(buffer_size=buffer_size)
dataset = raw_dataset.map(_parse_tfrecord(train, boxes), num_parallel_calls=tf.data.experimental.AUTOTUNE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return dataset
# load_tfrecord_dataset을 통해 train, validation 데이터셋을 생성하는 최종 메소드
def load_dataset(boxes, train=True, buffer_size=1024):
if train:
dataset = load_tfrecord_dataset(
tfrecord_name=TRAIN_TFRECORD_PATH,
train=train,
boxes=boxes,
buffer_size=buffer_size)
else:
dataset = load_tfrecord_dataset(
tfrecord_name=VALID_TFRECORD_PATH,
train=train,
boxes=boxes,
buffer_size=buffer_size)
return dataset
# 초기시점에 WarmUp부분을 도입해 learning rate가 천천히 증가할 수 있도록 학습 스텝에 따라 다른 Learning Rate이 적용
class PiecewiseConstantWarmUpDecay(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, boundaries, values, warmup_steps, min_lr, name=None):
super(PiecewiseConstantWarmUpDecay, self).__init__()
if len(boundaries) != len(values) - 1:
raise ValueError(
"The length of boundaries should be 1 less than the"
"length of values")
self.boundaries = boundaries
self.values = values
self.name = name
self.warmup_steps = warmup_steps
self.min_lr = min_lr
def __call__(self, step):
with tf.name_scope(self.name or "PiecewiseConstantWarmUp"):
step = tf.cast(tf.convert_to_tensor(step), tf.float32)
pred_fn_pairs = []
warmup_steps = self.warmup_steps
boundaries = self.boundaries
values = self.values
min_lr = self.min_lr
pred_fn_pairs.append(
(step <= warmup_steps,
lambda: min_lr + step * (values[0] - min_lr) / warmup_steps))
pred_fn_pairs.append(
(tf.logical_and(step <= boundaries[0],
step > warmup_steps),
lambda: tf.constant(values[0])))
pred_fn_pairs.append(
(step > boundaries[-1], lambda: tf.constant(values[-1])))
for low, high, v in zip(boundaries[:-1], boundaries[1:],
values[1:-1]):
pred = (step > low) & (step <= high)
pred_fn_pairs.append((pred, lambda: tf.constant(v)))
return tf.case(pred_fn_pairs, lambda: tf.constant(values[0]),
exclusive=True)
def MultiStepWarmUpLR(initial_learning_rate, lr_steps, lr_rate,
warmup_steps=0., min_lr=0.,
name='MultiStepWarmUpLR'):
assert warmup_steps <= lr_steps[0]
assert min_lr <= initial_learning_rate
lr_steps_value = [initial_learning_rate]
for _ in range(len(lr_steps)):
lr_steps_value.append(lr_steps_value[-1] * lr_rate)
return PiecewiseConstantWarmUpDecay(
boundaries=lr_steps, values=lr_steps_value, warmup_steps=warmup_steps,
min_lr=min_lr)
def hard_negative_mining(loss, class_truth, neg_ratio):
pos_idx = class_truth > 0
num_pos = tf.math.reduce_sum(tf.cast(pos_idx, tf.int32), axis=1)
num_neg = num_pos * neg_ratio
rank = tf.argsort(loss, axis=1, direction='DESCENDING')
rank = tf.argsort(rank, axis=1)
neg_idx = rank < tf.expand_dims(num_neg, 1)
return pos_idx, neg_idx
def MultiBoxLoss(num_class, neg_pos_ratio=3.0):
def multi_loss(y_true, y_pred):
num_batch = tf.shape(y_true)[0]
loc_pred, class_pred = y_pred[..., :4], y_pred[..., 4:]
loc_truth, class_truth = y_true[..., :4], tf.squeeze(y_true[..., 4:])
cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
temp_loss = cross_entropy(class_truth, class_pred)
pos_idx, neg_idx = hard_negative_mining(temp_loss, class_truth, neg_pos_ratio)
cross_entropy = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='sum')
loss_class = cross_entropy(
class_truth[tf.math.logical_or(pos_idx, neg_idx)],
class_pred[tf.math.logical_or(pos_idx, neg_idx)])
smooth_l1_loss = tf.keras.losses.Huber(reduction='sum')
loss_loc = smooth_l1_loss(loc_truth[pos_idx],loc_pred[pos_idx])
num_pos = tf.math.reduce_sum(tf.cast(pos_idx, tf.float32))
loss_class = loss_class / num_pos
loss_loc = loss_loc / num_pos
return loss_loc, loss_class
return multi_loss
boxes = default_box()
train_dataset = load_dataset(boxes, train=True)
# Training
boxes = default_box()
train_dataset = load_dataset(boxes, train=True)
model = SsdModel()
model.summary()
tf.keras.utils.plot_model(
model,
to_file=os.path.join(os.getcwd(), 'model.png'),
show_shapes=True,
show_layer_names=True
)
steps_per_epoch = DATASET_LEN // BATCH_SIZE
learning_rate = MultiStepWarmUpLR(
initial_learning_rate=1e-2,
lr_steps=[e*steps_per_epoch for e in [50, 70]],
lr_rate=0.1,
warmup_steps=5*steps_per_epoch,
min_lr=1e-4
)
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9, nesterov=True)
multi_loss = MultiBoxLoss(len(IMAGE_LABELS), neg_pos_ratio=3)
@tf.function
def train_step(inputs, labels):
with tf.GradientTape() as tape:
predictions = model(inputs, training=True)
losses = {}
losses['reg'] = tf.reduce_sum(model.losses) #unused. Init for redefine network
losses['loc'], losses['class'] = multi_loss(labels, predictions)
total_loss = tf.add_n([l for l in losses.values()])
grads = tape.gradient(total_loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return total_loss, losses
EPOCHS = 1
for epoch in range(0, EPOCHS):
for step, (inputs, labels) in enumerate(train_dataset.take(steps_per_epoch)):
load_t0 = time.time()
total_loss, losses = train_step(inputs, labels)
load_t1 = time.time()
batch_time = load_t1 - load_t0
print(f"\rEpoch: {epoch + 1}/{EPOCHS} | Batch {step + 1}/{steps_per_epoch} | Batch time {batch_time:.3f} || Loss: {total_loss:.6f} | loc loss:{losses['loc']:.6f} | class loss:{losses['class']:.6f} ",end = '',flush=True)
filepath = os.path.join(CHECKPOINT_PATH, f'weights_epoch_{(epoch + 1):03d}.h5')
model.save_weights(filepath)
# NMS 구현하기
def compute_nms(boxes, scores, nms_threshold=0.4, limit=200):
if boxes.shape[0] == 0:
return tf.constant([], dtype=tf.int32)
selected = [0]
idx = tf.argsort(scores, direction='DESCENDING')
idx = idx[:limit]
boxes = tf.gather(boxes, idx)
iou = _jaccard(boxes, boxes)
while True:
row = iou[selected[-1]]
next_indices = row <= nms_threshold
iou = tf.where(
tf.expand_dims(tf.math.logical_not(next_indices), 0),
tf.ones_like(iou, dtype=tf.float32),
iou
)
if not tf.math.reduce_any(next_indices):
break
selected.append(tf.argsort(
tf.dtypes.cast(next_indices, tf.int32), direction='DESCENDING')[0].numpy())
return tf.gather(idx, selected)
# 모델의 예측 결과를 디코딩해서 예측 확률을 토대로 NMS를 통해 최종 box와 score결과를 만들어 줌.
def decode_bbox_tf(predicts, boxes, variances=[0.1, 0.2]):
centers = boxes[:, :2] + predicts[:, :2] * variances[0] * boxes[:, 2:]
sides = boxes[:, 2:] * tf.math.exp(predicts[:, 2:] * variances[1])
return tf.concat([centers - sides / 2, centers + sides / 2], axis=1)
def parse_predict(predictions, boxes):
label_classes = IMAGE_LABELS
bbox_predictions, confidences = tf.split(predictions[0], [4, -1], axis=-1)
boxes = decode_bbox_tf(bbox_predictions, boxes)
scores = tf.math.softmax(confidences, axis=-1)
out_boxes = []
out_labels = []
out_scores = []
for c in range(1, len(label_classes)):
cls_scores = scores[:, c]
score_idx = cls_scores > 0.5
cls_boxes = boxes[score_idx]
cls_scores = cls_scores[score_idx]
nms_idx = compute_nms(cls_boxes, cls_scores)
cls_boxes = tf.gather(cls_boxes, nms_idx)
cls_scores = tf.gather(cls_scores, nms_idx)
cls_labels = [c] * cls_boxes.shape[0]
out_boxes.append(cls_boxes)
out_labels.extend(cls_labels)
out_scores.append(cls_scores)
out_boxes = tf.concat(out_boxes, axis=0)
out_scores = tf.concat(out_scores, axis=0)
boxes = tf.clip_by_value(out_boxes, 0.0, 1.0).numpy()
classes = np.array(out_labels)
scores = out_scores.numpy()
return boxes, classes, scores
# 이미지 패딩을 추가/제거해주는 함수
def pad_input_image(img, max_steps):
img_h, img_w, _ = img.shape
img_pad_h = 0
if img_h % max_steps > 0:
img_pad_h = max_steps - img_h % max_steps
img_pad_w = 0
if img_w % max_steps > 0:
img_pad_w = max_steps - img_w % max_steps
padd_val = np.mean(img, axis=(0, 1)).astype(np.uint8)
img = cv2.copyMakeBorder(img, 0, img_pad_h, 0, img_pad_w,
cv2.BORDER_CONSTANT, value=padd_val.tolist())
pad_params = (img_h, img_w, img_pad_h, img_pad_w)
return img, pad_params
def recover_pad(boxes, pad_params):
img_h, img_w, img_pad_h, img_pad_w = pad_params
box = np.reshape(boxes[0], [-1, 2, 2]) * [(img_pad_w + img_w) / img_w, (img_pad_h + img_h) / img_h]
boxes[0] = np.reshape(box, [-1, 4])
return boxes
# 이미지에 box를 그려주는 함수
def draw_box_on_face(img, boxes, classes, scores, box_index, class_list):
img_height = img.shape[0]
img_width = img.shape[1]
x_min = int(boxes[box_index][0] * img_width)
y_min = int(boxes[box_index][1] * img_height)
x_max = int(boxes[box_index][2] * img_width)
y_max = int(boxes[box_index][3] * img_height)
if classes[box_index] == 1:
color = (0, 255, 0)
else:
color = (0, 0, 255)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color, 2)
if len(scores) > box_index :
score = "{:.4f}".format(scores[box_index])
class_name = class_list[classes[box_index]]
label = '{} {}'.format(class_name, score)
position = (x_min, y_min - 4)
cv2.putText(img, label, position, cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
# 클라우드에 저장된 테스트용 이미지의 결과
filepath = os.path.join(PROJECT_PATH, 'checkpoints', 'weights_epoch_008.h5')
model.load_weights(filepath)
TEST_IMAGE_PATH = os.path.join(PROJECT_PATH, 'image_people.png')
img_raw = cv2.imread(TEST_IMAGE_PATH)
img_raw = cv2.resize(img_raw, (IMAGE_WIDTH, IMAGE_HEIGHT))
img = np.float32(img_raw.copy())
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img, pad_params = pad_input_image(img, max_steps=max(BOX_STEPS))
img = img / 255.0
boxes = default_box()
boxes = tf.cast(boxes, tf.float32)
predictions = model.predict(img[np.newaxis, ...])
pred_boxes, labels, scores = parse_predict(predictions, boxes)
pred_boxes = recover_pad(pred_boxes, pad_params)
for box_index in range(len(pred_boxes)):
draw_box_on_face(img_raw, pred_boxes, labels, scores, box_index, IMAGE_LABELS)
plt.imshow(cv2.cvtColor(img_raw, cv2.COLOR_BGR2RGB))
plt.show()



