
human pose estimation
2D HPE 는 2D 이미지에서 (x, y) 2차원 좌표들을 찾아내고
3D HPE 는 2D 이미지에서 (x, y, z) 3차원 좌표들을 찾아내는 기술
Top-down
모든 사람의 정확한 keypoint를 찾기 위해 object detection 을 사용
crop한 이미지 내에서 keypoint 를 찾아내는 방법으로 표현
detector가 선행되어야 하고 모든 사람마다 알고리즘을 적용해야 하기 때문에 사람이 많이 등장할 때는 느리다는 단점
Bottom-up
detector가 없고 keypoint를 먼저 검출합니다.
한 사람에 해당하는 keypoint 를 clustering함.
detector 가 없기 때문에 다수의 사람이 영상에 등장하더라도 속도 저하가 크지 않습니다.
op down 방식에 비해 keypoint 검출 범위가 넓어 성능이 떨어진다는 단점
Efficient Object Localization
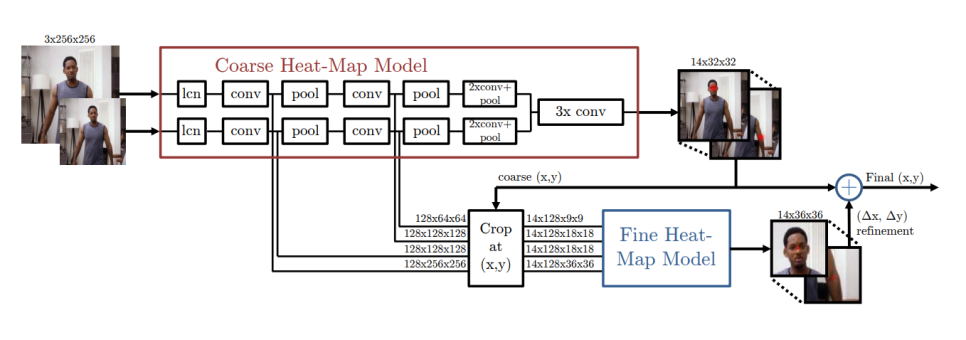
keypoint의 위치를 직접 예측하기보다 keypoint가 존재할 확률 분포를 학습
coarse model 에서 32x32 heatmap 을 대략적으로 추출한 후 multi resolution 입력을 coarse heatmap 기준으로 crop 한 뒤 fine model 에서 refinement 를 수행합니다.
coarse model 과 fine model 이 같은 모델이며 weight 를 공유합니다. 목적이 같기 때문에 빠른 학습이 가능하고 메모리, 저장공간을 효율적으로 사용할 수 있습니다.
CPM (Convolutional Pose Machines)
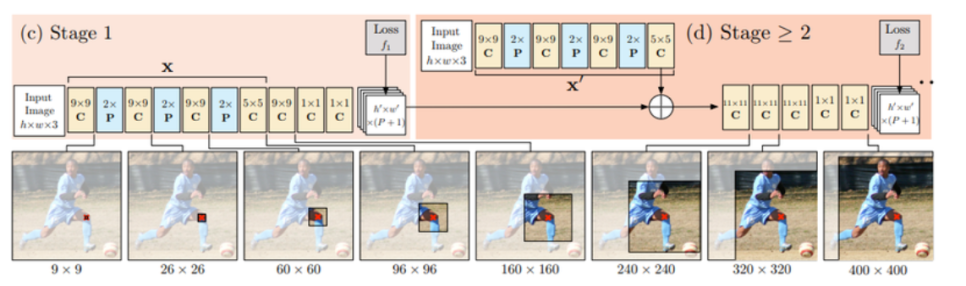
end-to-end 로 학습할 수 있는 모델을 제안
Stage 1은 image feature를 계산하는 역할
stage 2는 keypoint를 예측하는 역할
g1과 g2 모두 heatmap 을 출력하게 만들어서 재사용이 가능한 부분은 weight sharing 할 수 있도록 세부 모델을 설계
stage 2 부터는 입력이 heatmap(image feature)이 되기 때문에 stage 단계를 거칠수록 keypoint가 refinement 되는 효과
tage 단위로 pretraining 을 한 후 다시 하나의 모델로 합쳐서 학습을 합니다.
receptive field 를 넓게 만드는 multi stage refinement 방법이 성능 향상에 크게 기여
Stacked Hourglass Network
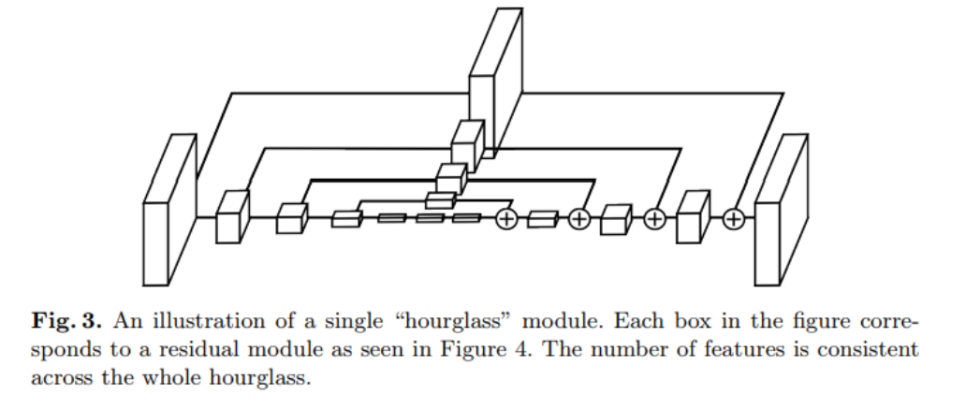
기본 구조는 모래시계 같은 모양
feature map 크기가 작아졌다 커지는 구조여서 hourglass 라고 표현
Conv layer 와 pooling 으로 이미지(또는 feature) 를 인코딩 하고, upsampling layer 를 통해 feature map 의 크기를 키우는 방향으로 decoding
pooling으로 image의 global feature를 찾고 upsampling으로 local feature를 고려
Deep High-Resolution Network (HRNet)
down sample layer를 만들고 작아진 layer feautre 정보를 다시 up sampling해서 원본 해상도 크기에 적용하는 모델
heatmap supervision이 없음.
SimpleBaseline
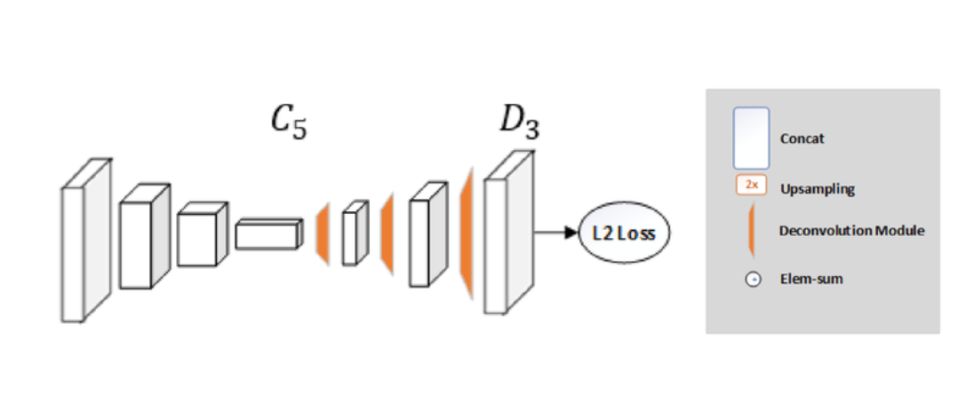
encoder 가 무겁고 (resnet50 등 backbone 사용) decoder 는 가벼운 모델을 사용
skip connection 이 없다.
encoder : conv layers
decoder : deconv module + upsampling
conv model 로 resnet을 사용
deconv-bn-relu 이 단계가 3개로 이루어져 있습니다. deconv 는 256 filter size, 4x4 kernel, stride 2 로 2배씩 feature map이 커집니다.
마지막 출력 레이어는 k 개의 1x1 conv layer로 구성
# SimpleBaseline - tf2
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
resnet = tf.keras.applications.resnet.ResNet50(include_top=False, weights='imagenet')
# deconv module
upconv1 = tf.keras.layers.Conv2DTranspose(256, kernel_size=(4,4), strides=(2,2), padding='same')
bn1 = tf.keras.layers.BatchNormalization()
relu1 = tf.keras.layers.ReLU()
upconv2 = tf.keras.layers.Conv2DTranspose(256, kernel_size=(4,4), strides=(2,2), padding='same')
bn2 = tf.keras.layers.BatchNormalization()
relu2 = tf.keras.layers.ReLU()
upconv3 = tf.keras.layers.Conv2DTranspose(256, kernel_size=(4,4), strides=(2,2), padding='same')
bn3 = tf.keras.layers.BatchNormalization()
relu3 = tf.keras.layers.ReLU()
# deconv module에서 중복을 제거
def _make_deconv_layer(num_deconv_layers):
seq_model = tf.keras.models.Sequential()
for i in range(num_deconv_layers):
seq_model.add(tf.keras.layers.Conv2DTranspose(256, kernel_size=(4,4), strides=(2,2), padding='same'))
seq_model.add(tf.keras.layers.BatchNormalization())
seq_model.add(tf.keras.layers.ReLU())
return seq_model
upconv = _make_deconv_layer(3)
final_layer = tf.keras.layers.Conv2D(17, kernel_size=(1,1), padding='same')
# 각각의 요소를 합쳐 모델을 완성
inputs = keras.Input(shape=(256, 192, 3))
x = resnet(inputs)
x = upconv(x)
out = final_layer(x)
model = keras.Model(inputs, out)
model.summary()
# 가상의 이미지를 넣어서 출력이 잘 나오는지 확인
np_input = np.zeros((1,256,192,3), dtype=np.float32)
tf_input = tf.convert_to_tensor(np_input, dtype=tf.float32)
print('input shape')
print (tf_input.shape)
print('\n')
tf_output = model(tf_input)
print('output shape')
print (tf_output.shape)
print (tf_output[0,:10,:10,:10])



