레이어 (layer)
- 여러 개의 논리적인 개체가 층을 이루어서 하나의 물체를 구성하는 것
- Linear 레이어는 선형 변환을 활용해 데이터를 특정 차원으로 변환함.
- Linear 레이어는 입력의 차원, 출력의 차원에 해당하는 가중치(Weight)를 가짐.
- 가중치(Weight)의 모든 요소를 파라미터라고 함.
- 지나치게 많은 파라미터는 오버피팅을 야기함.
- Dense클래스 속 use_bias파라미터를 True로 바꿔주면 편향 값을 더해줄 수 있음.
- tf.keras.layers.Layer.count_params(): 총 파라미터 개수를 출력함.
import tensorflow as tf
batch_size = 64
boxes = tf.zeros((batch_size, 4, 2)) # Tensorflow는 Batch를 기반으로 동작함.
first_linear = tf.keras.layers.Dense(units=1, use_bias=False) # units은 출력 차원 수를 의미함.
first_out = first_linear(boxes)
first_out = tf.squeeze(first_out, axis=-1) # (4, 1)을 (4,)로 변환해줌. (차원 축소)
Convolution
- 이미지를 필터로 훑으며 각 픽셀을 곱하여 더함.
- 이미지와 필터가 겹치는 부분의 값을 서로 곱한 후 그 값을 모두 더하면 새로운 이미지의 한 픽셀값이 됨.
- [ 필터의 개수 x 필터의 가로 x 필터의 세로 ] 로 이루어진 가중치(Weight)를 가짐.
- 필터 사이즈를 키우면 파라미터 사이즈 및 연산량이 커지며, Accuracy도 떨어지게 될 가능성이 높음.
- 입력 데이터의 수용 영역(Receptive Field)이 충분히 커야 정확한 탐지(detection)가 가능함.
- Max Pooling 레이어를 통해 효과적으로 수용 영역을 키우고, 정보 집약 효과를 극대화할 수 있음.
- dialted convolutions은 수용 영역(receptive field)을 효율적으로 넓힐 수 있으며, pooling이후 unpooling 할 때 해상도를 높일 수 있음.
import tensorflow as tf
batch_size = 64
pic = tf.zeros((batch_size, 1920, 1080, 3))
conv_layer = tf.keras.layers.Conv2D(filters=16,
kernel_size=(5, 5),
strides=5,
use_bias=False)
conv_out = conv_layer(pic)
flatten_out = tf.keras.layers.Flatten()(conv_out)

Deconvolution
- Convolution의 결과를 역재생해 원본 이미지와 최대한 유사한 정보를 복원해냄.
1. 패키지 임포트 및 MNIST 데이터셋 로딩
2. AutoEncoder 모델 구성
3. AutoEncoder 모델 훈련
4. AutoEncoder 복원 테스트
1. 패키지 임포트 및 MNIST 데이터셋 로딩
import numpy as np
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
import json
import matplotlib.pyplot as plt
# MNIST 데이터 로딩
(x_train, _), (x_test, _) = mnist.load_data() # x_train자신이 라벨이 됨.
x_train = np.expand_dims(x_train, axis=3)
x_test = np.expand_dims(x_test, axis=3)
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
2. AutoEncoder 모델 구성
# Input 부분
input_shape = x_train.shape[1:]
input_img = Input(shape = input_shape)
# Encoder 부분
encode_conv_layer_1 = Conv2D(16, (3, 3), activation='relu', padding='same')
encode_pool_layer_1 = MaxPooling2D((2, 2), padding='same')
# Decoder 부분
decode_conv_layer_1 = Conv2D(4, (3, 3), activation='relu', padding='same')
decode_upsample_layer_1 = UpSampling2D((2, 2))
-------------------------------------------
# Conv2DTranspose를 활용한 모델
from tensorflow.keras.layers import Conv2DTranspose
decode_conv_layer_1 = Conv2DTranspose(4, (3, 3), activation='relu', padding='same')
decode_upsample_layer_1 = UpSampling2D((2, 2))
3. AutoEncoder 모델 훈련
autoencoder.compile( optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=2,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
4. AutoEncoder 복원 테스트
x_test_10 = x_test[:10]
x_test_hat = autoencoder.predict(x_test_10) # AutoEncoder 모델의 이미지 복원생성
x_test_imgs = x_test_10.reshape(-1, 28, 28)
x_test_hat_imgs = x_test_hat.reshape(-1, 28, 28)

Upsampling의 종류
- Nearest Neighbor : 복원해야 할 값을 가까운 값으로 복제함. (디폴트)
- Bed of Nails : 복원해야 할 값을 0으로 처리한다.
- Max Unpooling : Max Pooling 때 버린 값을 실은 따로 기억해 두었다가 그 값으로 복원함.
합성곱 신경망 (Convolution Neural Network)
- 이미지 처리분야에서 뛰어난 성능을 발휘함.
- 합성곱은 입력데이터의 일부에 가중치를 적용해나감.
- 이동하면서 동일한 필터(= 커널 = 가중치 도장 = 뉴런)를 적용함.
- 특성맵(feauture map): 합성곱 계산을 통해 얻은 출력
- 입력 -> 필터(커널) -> 특성맵
- 합성곱층(Conv2D)에서 특성맵을 생성하고, 풀링층(MaxPool2D)에서 크기를 줄이는 구조가 쌍을 이룸.
세임 패딩 (same padding)
- 입력과 특성맵의 크기를 동일하게 만들기 위해 입력 주위에 0으로 가상의 원소를 채우는 것
- 이미지의 모서리에 있는 정보를 잃어버리지 않도록 해줌.
- .Conv2D( 필터 개수, kernel_size=(3, 3), activation = 'relu' , padding = 'same' )
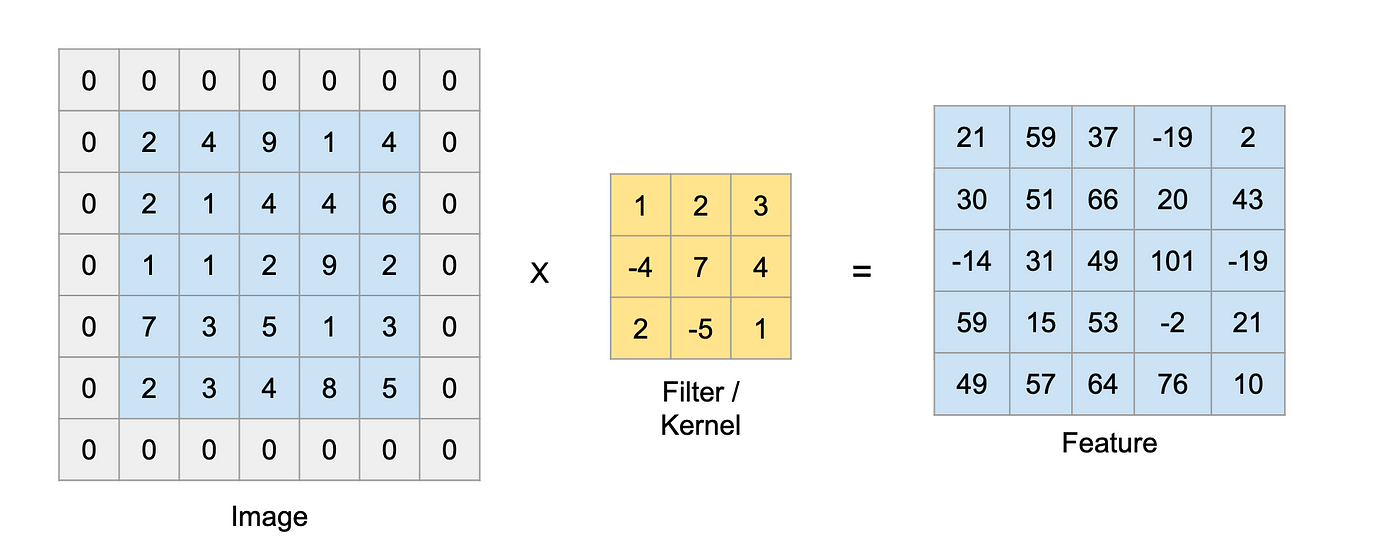
밸리드 패딩 (valid padding)
- 패딩없이 순수한 입력배열에서만 합성곱을 하여 특성맵을 만드는 것
- padding매개변수의 디폴트값
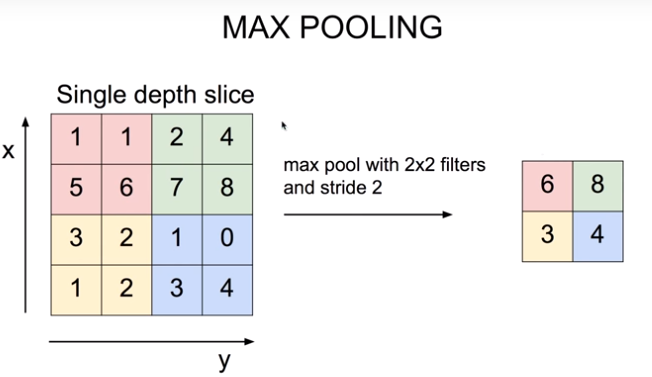
풀링 (pooling)
- 특성맵의 너비와 높이를 줄임.
- 특성맵의 개수는 변하지 않고 그대로임.
- 커널에 가중치가 없음. -> 최대 풀링과 평균 풀링을 사용
- 최대(max) 풀링: 도장을 찍은 영역에서 가장 큰값을 고름 / .MaxPooling2D( 풀링의 크기 )
- 평균(average) 풀링: 도장을 찍은 영역에서 평균값을 계산함 / .AveragePooling2D( 풀링의 크기 )
- 풀링의 크기와 스트라이드는 같음. (풀링의 크기가 (2,2)이면 가로세로 2칸씩 겹치지 않고 이동함. -> 특성맵의 크기를 절반으로 줄임.)