
텍스트 요약 (Text Summarization)
- 긴 길이의 문서 원문을 핵심 주제만으로 구성된 짧은 요약(Summary) 문장들로 변환하는 것
- 요약 전후의 정보손실 발생이 최소화되어야 함.
- 추출적(Extractive) 요약과 추상적(Abstractive) 요약으로 나뉨.
추출적 요약 (Extractive Summarization)
- 원문에서 문장들을 추출해서 요약하는 방식
- 핵심적인 문장만 꺼내와서 요약문을 만드는 방식 => 문장 분류 (Text Classification)
- 요약된 문장들 간의 호응이 자연스럽지 않을 수도 있음.
- 전통적인 머신 러닝 방식에 속하는 텍스트 랭크(TextRank)와 같은 알고리즘을 사용함.
- 패키지 Summa의 summarize모듈을 활용함. from summa.summarizer import summarize
추상적 요약 (Abstractive Summarization)
- 원문으로부터 내용이 요약된 새로운 문장을 생성해내는 것
- 자연어 생성 (Natural Language Generation, NLG)의 영역임.
컨텍스트 벡터 (context vector)
- 문맥 정보를 갖고 있는 벡터
- 첫 번째 RNN인 인코더는 원문을 하나의 고정된 벡터인 '컨텍스트 벡터'로 변환함.
- 두 번째 RNN인 디코더는 컨텍스트 벡터를 전달받아 한 단어씩 생성해내어 요약 문장을 완성함.
텍스트 정규화 (text normalization)
- 기계 학습 전에 미리 같은 표현은 통일시켜주어 기계의 연산량을 줄여주는 방법
it'll = it will
mustn't = must not
정수 인코딩
- 각 단어에 고유한 정수를 맵핑하는 작업 = 단어 집합 (vocabulary)을 만드는 작업
- Tokenizer클래스의 fit_on_texts 메서드를 활용함.
- 생성된 단어 집합은 src_tokenizer.word_index에 저장되어 있음.
recurrent dropout
- dropout을 레이어가 아닌, 타임스텝마다 해주는 방식
- 타임스텝의 입력을 랜덤으로 생략함.
- regularization을 해주며, 과적합을 방지하는 효과가 있음.
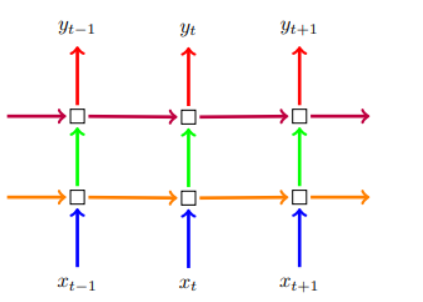
어텐션 (Attention)
- 단어들 간의 유사도를 구하는 메커니즘
- 쿼리(Query), 키(Key), 밸류(Value) 는 기본적으로 '단어 정보를 함축한 벡터'임.
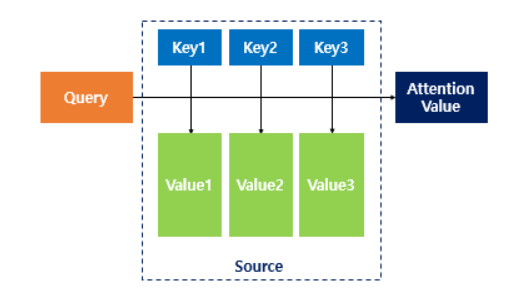
1. 주어진 쿼리(Query)에 대해서 모든 키(Key)와의 유사도를 각각 구함.
2. 구해낸 유사도를 키(Key)와 맵핑되어있는 각각의 밸류(Value)에 반영해줌.
3. 유사도가 반영된 밸류(Value)를 모두 더해서 뭉쳐줌. => 어텐션 밸류 (Attention Value)
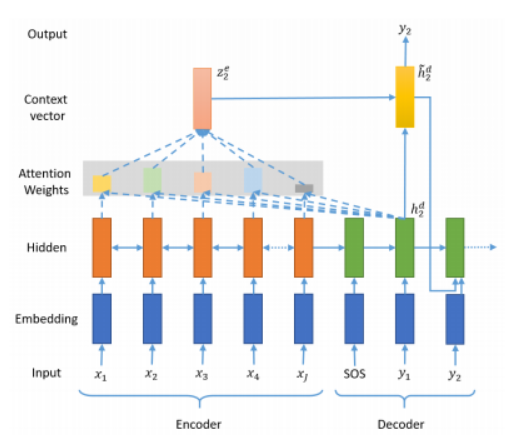
- 기존의 컨텍스트 벡터보다 인코더의 정보를 적극적으로 활용하여 성능을 끌어올림.
- 인코더의 모든 step의 hidden state의 정보가 컨텍스트 벡터에 전부 반영되도록 함.
- 디코더의 현재 time step 예측에 인코더의 각 step이 얼마나 영향을 미치는지에 따른 가중합으로 계산함.
- 인코더의 hidden state 가중치 값은 디코더의 현재 스텝이 어디냐에 따라 계속 달라짐.
- 디코더의 현재 스텝에 따라 동적으로 달라지는 인코더의 컨텍스트 벡터를 사용해서 현재의 예측에 활용하면, 디코더가 좀 더 정확한 예측을 할 수 있게 됨.
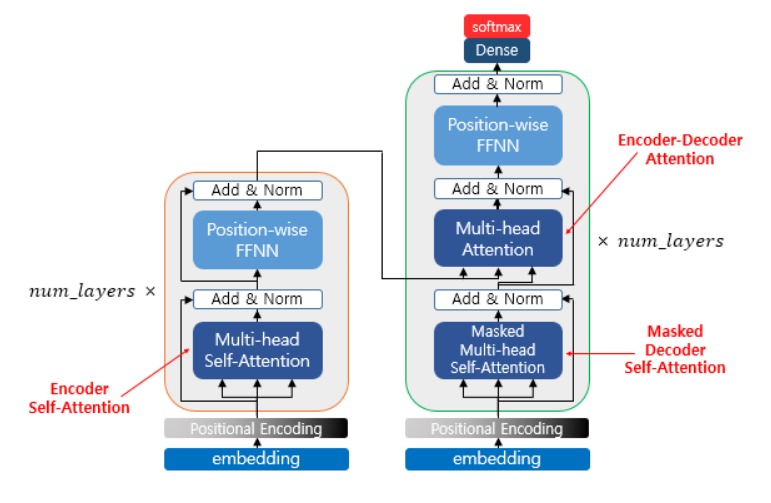
- 인코더 셀프 어텐션: 인코더의 입력으로 들어간 문장 내 단어간의 유사도를 구함.
- 마스크드 디코더 셀프 어텐션: 단어를 1개씩 생성하는 디코더가 이미 생성된 앞 단어와의 유사도를 구함.
- 인코더-디코더 어텐션: 디코더가 잘 예측하기 위해 인코더에 입력된 단어들과 유사도를 구함.
스케일드 닷 프로덕트 어텐션 (Scaled Dot Product Attention)
- 내적(dot product)을 통해 단어 벡터 간의 유사도를 구한 후에, 특정 값을 분모로 나눠주는 방식(Scaling)으로 Q와 K의 유사도를 구함.
- 유사도를 0과 1사이의 값으로 정규화해주기 위해 소프트맥스 함수를 사용함.
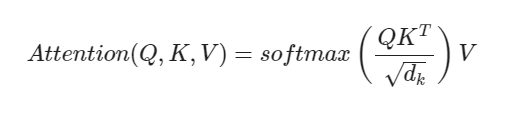
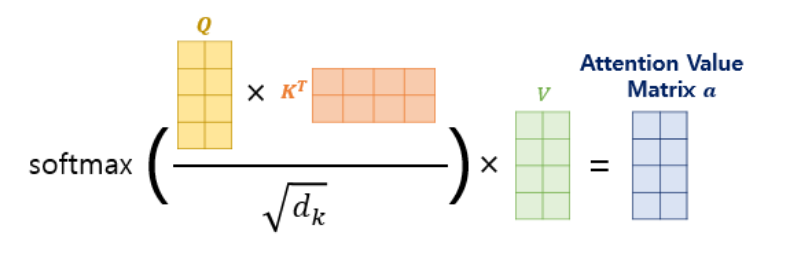
def scaled_dot_product_attention( query, key, value, mask ):
# 어텐션 가중치는 Q와 K의 내적
matmul_qk = tf.matmul( query, key, transpose_b=True )
# 가중치를 정규화
depth = tf.cast( tf.shape(key)[-1], tf.float32 )
logits = matmul_qk / tf.math.sqrt(depth)
# 패딩에 마스크 추가
if mask is not None:
logits += (mask * -1e9)
# softmax적용
attention_weights = tf.nn.softmax( logits, axis=-1 )
# 최종 어텐션은 가중치와 V의 내적
output = tf.matmul( attention_weights, value )
return output
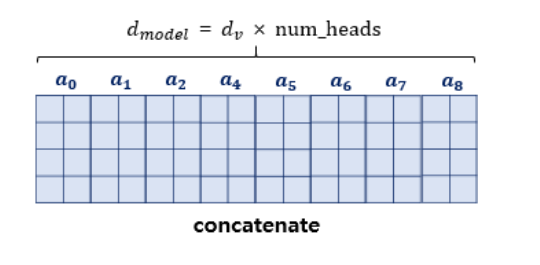
멀티헤드 어텐션 ( MultiHeadAttention )
- 어텐션을 병렬로 수행하는 것
- 한 번의 어텐션만 수행했다면 놓칠 수도 있었던 정보를 캐치해냄.
- 내부적으로는 스케일드 닷 프로덕트 어텐션 함수를 호출함.
- num_heads: 트랜스포머가 병렬적으로 몇 개의 어텐션 연산을 수행할지 결정하는 하이퍼파라미터
class MultiHeadAttention( tf.keras.layers.Layer ):
def __init__( self, d_model, num_heads, name="multi_head_attention" ):
super( MultiHeadAttention, self ).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.query_dense = tf.keras.layers.Dense( units=d_model )
self.key_dense = tf.keras.layers.Dense( units=d_model )
self.value_dense = tf.keras.layers.Dense( units=d_model )
self.dense = tf.keras.layers.Dense( units=d_model )
def split_heads( self, inputs, batch_size ):
inputs = tf.reshape( inputs, shape=( batch_size, -1, self.num_heads, self.depth ) )
return tf.transpose( inputs, perm=[0, 2, 1, 3] )
def call( self, inputs ):
query, key, value, mask = inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = tf.shape(query)[0]
query = self.query_dense( query )
key = self.key_dense( key )
value = self.value_dense( value )
query = self.split_heads( query, batch_size )
key = self.split_heads( key, batch_size )
value = self.split_heads( value, batch_size )
scaled_attention = scaled_dot_product_attention( query, key, value, mask )
scaled_attention = tf.transpose( scaled_attention, perm=[0, 2, 1, 3] )
# 어텐션 연산 후의 각 결과를 다시 연결(concatenate)함.
concat_attention = tf.reshape( scaled_attention, (batch_size, -1, self.d_model) )
# 최종 결과에도 Dense를 한 번 더 적용함.
outputs = self.dense( concat_attention )
return outputs



