
챗봇의 유형
- 대화형 챗봇: 자연어처리를 기반으로 자연스럽게 대화가 가능한 챗봇
- 트리형(버튼) 챗봇: 정해진 트리구조를 따라 답변을 얻는 형태
- 추천형 챗봇: 질문을 던지면 사전에 정의된 답변의 리스트를 알고리즘 결과의 우선순위별로 보여줌.
- 시나리오형 챗봇: 원하는 서비스 혹은 아웃풋 제공을 위하여 정해진 시나리오를 수행하는 챗봇
- 결합형 챗봇: 비즈니스 목적에 따라 위의 챗봇 유형들을 결합해서 설계
마스킹 (Masking)
- 특정 값들을 가려서 실제 연산에 방해가 되지 않도록 하는 기법
- 마스킹에는 '패딩 마스킹'과 '룩 어헤드 마스킹'이 있음.
패딩 마스킹 (Padding Masking)
- 패딩으로 주어진 숫자0을 실제 어텐션 연산에서 제외하기 위해 숫자0의 위치를 체크하는 것
- 숫자가 0인 위치에서는 1이 나오고, 숫자 0이 아닌 위치에서는 0인 벡터를 출력함.
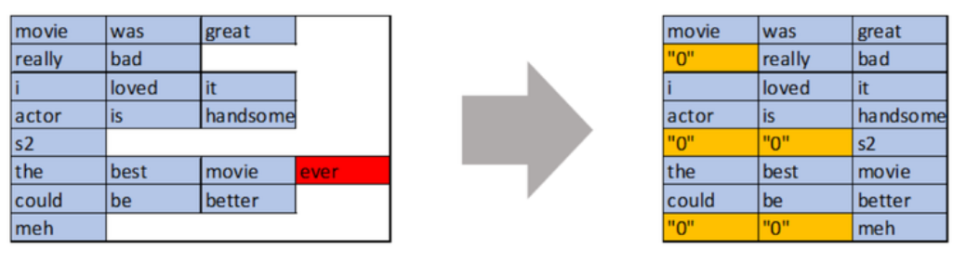
def create_padding_mask(x):
mask = tf.cast( tf.math.equal( x, 0 ), tf.float32 )
return mask[ :, tf.newaxis, tf.newaxis, : ]
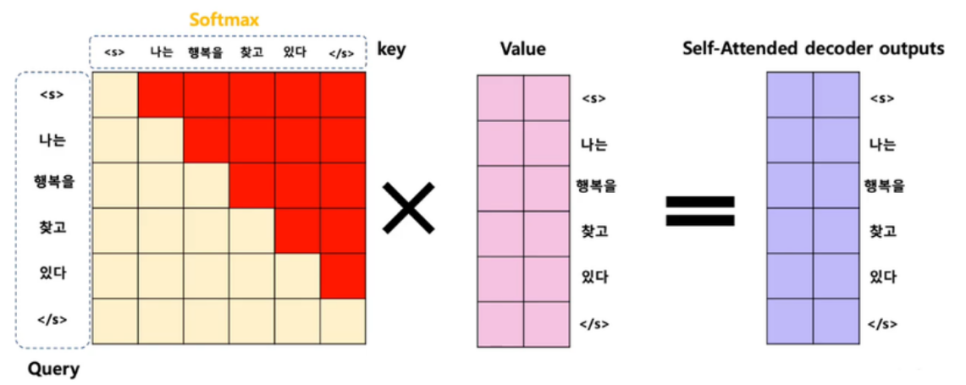
룩 어헤드 마스킹 (Look-ahead masking)
- 자신보다 다음에 나올 단어를 참고하지 않도록 가리는 기법
- 어텐션을 수행할 때, Query 단어 뒤에 나오는 Key 단어들에 대해서만 마스킹함.
- 현재 단어를 기준으로 이전 단어들하고만 유사도를 구함.
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
look_ahead_mask = 1 - tf.linalg.band_part( tf.ones( (seq_len, seq_len) ), -1, 0)
padding_mask = create_padding_mask(x)
return tf.maximum( look_ahead_mask, padding_mask )
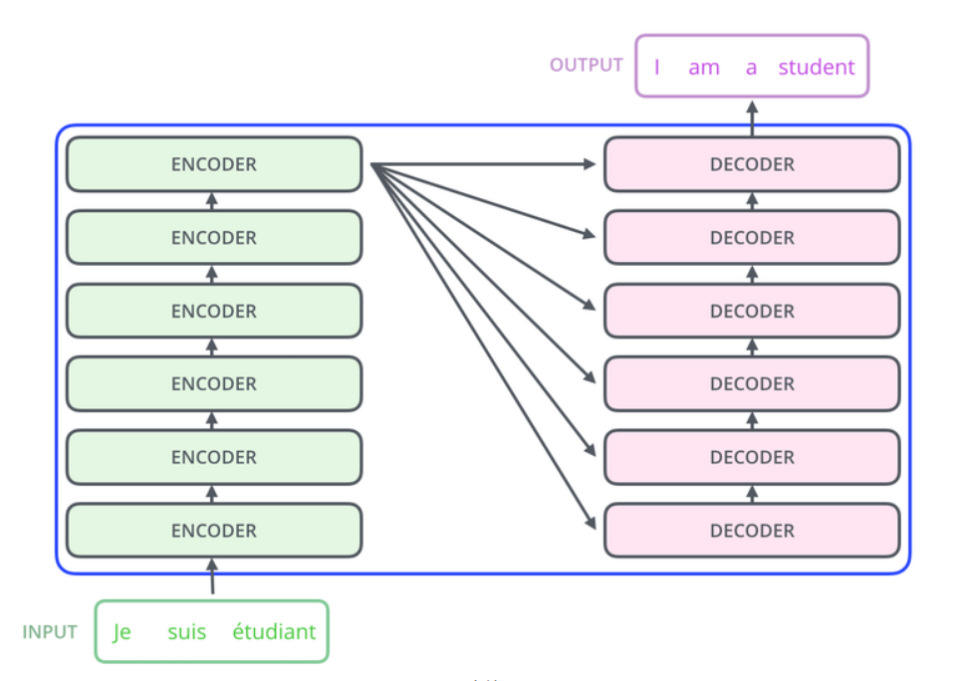
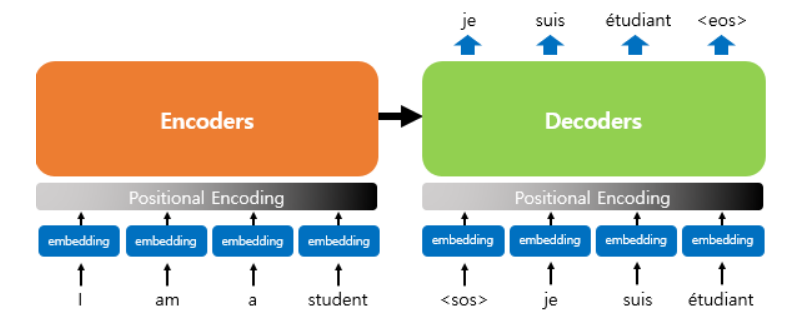
트랜스포머 (Transformer)
- LSTM에 비해 훨씬 뛰어난 처리 속도를 보이며, RNN 모델이 가지는 장기 의존성에 강하여 매우 긴 길이의 문장을 처리하는 데 유리함.
- 기본적으로 인코더와 디코더 구성을 갖고 있음.
- 입력 문장은 누적해 쌓아 올린 인코더의 층을 통해서 정보를 뽑아냄.
- 누적해 쌓아 올린 디코더의 층을 통해서 출력 문장의 단어를 하나씩 만들어감.

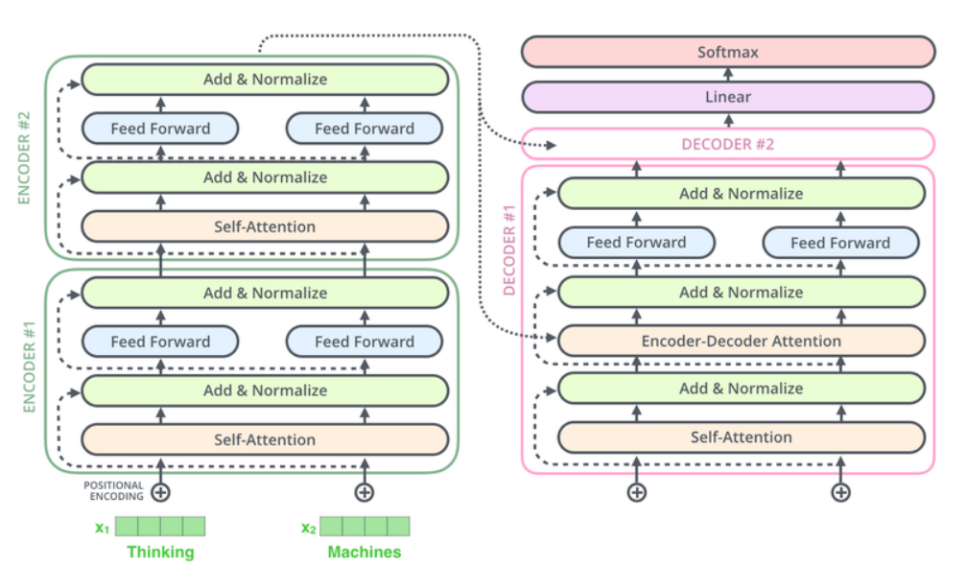
- 기존 RNN 계열의 모델들과 다른 점은 임베딩 벡터에 어떤 값을 더해준 뒤에 입력으로 사용한다는 점임.
임베딩 벡터 + 포지셔널 인코딩 (positional Encoding)
- 트랜스포머는 입력을 받을 때 문장에 있는 단어들을 1개씩 순차적으로 받는 것이 아니라, 문장에 있는 모든 단어를 한꺼번에 받음.
- 같은 단어라도 그 단어가 문장의 몇 번째 어순으로 입력되었는지를 모델에 추가로 알려 주기 위해, 단어의 임베딩 벡터에다가 위치 정보를 가진 벡터인 포지셔널 인코딩 값을 더해서 모델의 입력으로 삼음.
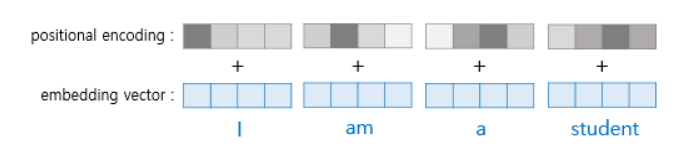
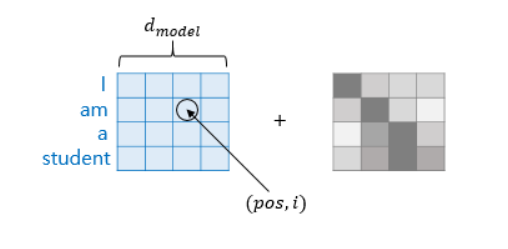
- 트랜스포머는 사인 함수와 코사인 함수의 값을 임베딩 벡터에 더해줌으로써 단어의 순서 정보를 나타냄.
d model: 임베딩 벡터의 차원
pos: 입력 문장에서의 임베딩 벡터의 위치
i: 임베딩 벡터 내의 차원의 인덱스
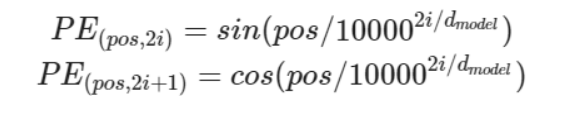
# 포지셔널 인코딩 레이어
class PositionalEncoding( tf.keras.layers.Layer ):
def __init__( self, position, d_model ):
super( PositionalEncoding, self ).__init__()
self.pos_encoding = self.positional_encoding( position, d_model )
def get_angles( self, position, i, d_model ):
angles = 1 / tf.pow( 10000, (2 * (i // 2) ) / tf.cast( d_model, tf.float32 ))
return position * angles
def positional_encoding( self, position, d_model ):
# 각도 배열 생성
angle_rads = self.get_angles(
position = tf.range( position, dtype=tf.float32 )[ : , tf.newaxis],
i = tf.range( d_model, dtype=tf.float32 )[tf.newaxis, : ],
d_model = d_model)
# 배열의 짝수 인덱스에는 sin 함수 적용
sines = tf.math.sin( angle_rads[ : , 0: :2] )
# 배열의 홀수 인덱스에는 cosine 함수 적용
cosines = tf.math.cos( angle_rads[ : , 1: :2] )
# sin과 cosine이 교차되도록 재배열
pos_encoding = tf.stack( [sines, cosines], axis=0 )
pos_encoding = tf.transpose( pos_encoding, [1, 2, 0] )
pos_encoding = tf.reshape( pos_encoding, [position, d_model] )
pos_encoding = pos_encoding[ tf.newaxis, ... ]
return tf.cast( pos_encoding, tf.float32 )
def call( self, inputs ):
return inputs + self.pos_encoding[ : , :tf.shape(inputs)[1], : ]
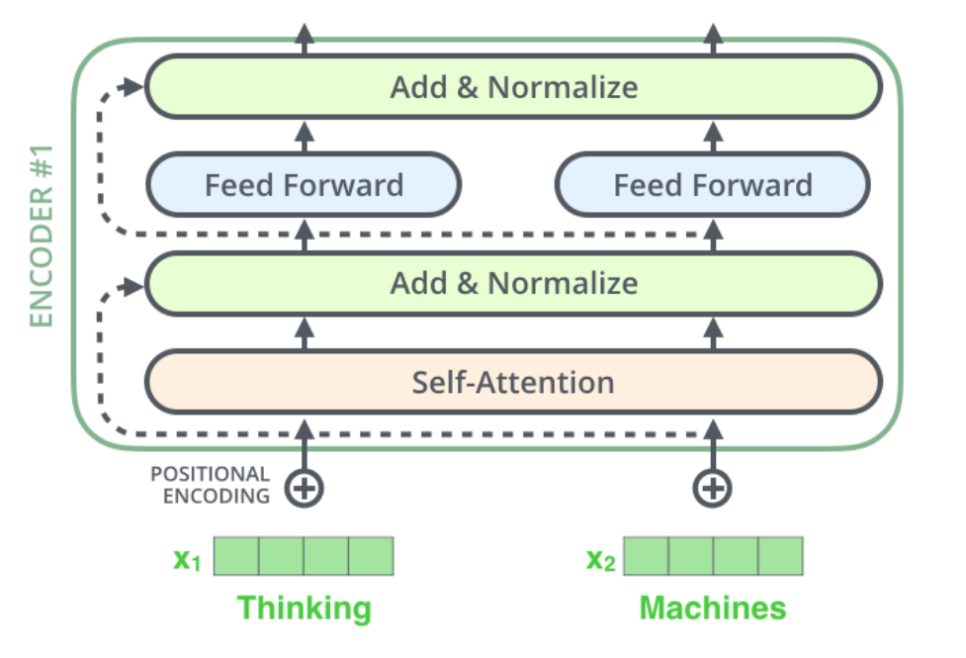
트랜스포머의 인코더 (encoder)
- 인코더 셀프 어텐션과 피드 포워드 신경망으로 구성됨.
def encoder_layer( units, d_model, num_heads, dropout, name="encoder_layer" ):
inputs = tf.keras.Input( shape=(None, d_model), name="inputs" )
# 패딩 마스크 사용
padding_mask = tf.keras.Input( shape=(1, 1, None), name="padding_mask" )
# 셀프 어텐션 : 멀티 헤드 어텐션 수행
attention = MultiHeadAttention( d_model, num_heads, name="attention" )({
'query': inputs,
'key': inputs,
'value': inputs,
'mask': padding_mask
})
attention = tf.keras.layers.Dropout( rate=dropout )( attention )
attention = tf.keras.layers.LayerNormalization( epsilon=1e-6 )( inputs + attention )
# 피드 포워드 신경망: 2개의 완전연결층
outputs = tf.keras.layers.Dense( units=units, activation='relu' )( attention )
outputs = tf.keras.layers.Dense( units=d_model )( outputs )
outputs = tf.keras.layers.Dropout( rate=dropout )( outputs )
outputs = tf.keras.layers.LayerNormalization( epsilon=1e-6 )( attention + outputs )
return tf.keras.Model( inputs=[inputs, padding_mask], outputs=outputs, name=name )
# 인코더 층을 쌓아 인코더 만들기
def encoder(vocab_size,
num_layers,
units,
d_model,
num_heads,
dropout,
name="encoder"):
inputs = tf.keras.Input( shape=(None,), name="inputs" )
# 패딩 마스크 사용
padding_mask = tf.keras.Input( shape=(1, 1, None), name="padding_mask" )
# 임베딩 레이어
embeddings = tf.keras.layers.Embedding( vocab_size, d_model )( inputs )
embeddings *= tf.math.sqrt( tf.cast( d_model, tf.float32 ) )
# 포지셔널 인코딩
embeddings = PositionalEncoding( vocab_size, d_model )( embeddings )
outputs = tf.keras.layers.Dropout( rate=dropout )( embeddings )
# num_layers만큼 쌓아올린 인코더의 층.
for i in range( num_layers ):
outputs = encoder_layer(
units=units,
d_model=d_model,
num_heads=num_heads,
dropout=dropout,
name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model( inputs=[inputs, padding_mask], outputs=outputs, name=name )
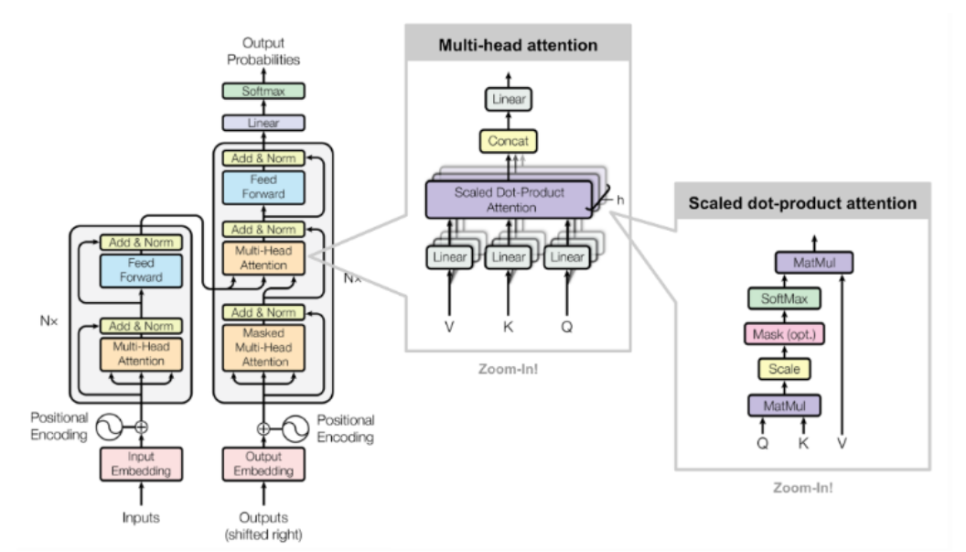
트랜스포머의 디코더 (decoder)
- 마스크드 디코더 셀프 어텐션 , 인코더-디코더 어텐션 , 피드 포워드 신경망으로 구성됨.
- 인코더-디코더 어텐션은 Query가 디코더의 벡터인 반면에, Key와 Value가 인코더의 벡터임.
- 스케일드 닷 프로덕트 어텐션을 멀티 헤드 어텐션으로 병렬적으로 수행함.
def decoder_layer( units, d_model, num_heads, dropout, name="decoder_layer" ):
inputs = tf.keras.Input( shape=(None, d_model), name="inputs" )
enc_outputs = tf.keras.Input( shape=(None, d_model), name="encoder_outputs" )
look_ahead_mask = tf.keras.Input( shape=(1, None, None), name="look_ahead_mask" )
padding_mask = tf.keras.Input( shape=(1, 1, None), name='padding_mask' )
# 마스크드 디코더 셀프 어텐션: 멀티 헤드 어텐션 수행
attention1 = MultiHeadAttention( d_model, num_heads, name="attention_1" )( inputs={
'query': inputs,
'key': inputs,
'value': inputs,
'mask': look_ahead_mask
})
attention1 = tf.keras.layers.LayerNormalization( epsilon=1e-6 )( attention1 + inputs )
# 인코더-디코더 어텐션: 멀티 헤드 어텐션 수행
attention2 = MultiHeadAttention( d_model, num_heads, name="attention_2" )( inputs={
'query': attention1,
'key': enc_outputs,
'value': enc_outputs,
'mask': padding_mask
})
attention2 = tf.keras.layers.Dropout( rate=dropout )( attention2 )
attention2 = tf.keras.layers.LayerNormalization( epsilon=1e-6 )( attention2 + attention1 )
# 피드 포워드 신경망: 2개의 완전연결층
outputs = tf.keras.layers.Dense( units=units, activation='relu' )( attention2 )
outputs = tf.keras.layers.Dense( units=d_model )( outputs )
outputs = tf.keras.layers.Dropout( rate=dropout )( outputs )
outputs = tf.keras.layers.LayerNormalization( epsilon=1e-6 )( outputs + attention2 )
return tf.keras.Model( inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)



