인공지능 수첩 ( Object keypoint estimation 알고리즘 / 이미지 피라미드 / sliding window / dlib의 face detector / 이미지 읽기의 flag / 랜드마크/ OpenCV / 이미지 데이터 / 컬러 스페이스 )

비트맵 방식 (=래스터 방식)
- 빨강(R), 초록(G), 파랑(B) 세 가지 색의 강도로 표현되는 픽셀로 구성된 점 하나하나의 색상 값을 저장하는 방식
- 보통 한 점마다 각 색상별로 8비트를 사용(2^8 = 256)하여 0~255 사이의 값으로 해당 색의 감도를 표시함.
- 사진 파일들
벡터 방식
- 상대적인 점과 선의 위치를 방정식으로 기록해서 저장하는 방식
- 확대 및 축소에 따라 화면의 각 픽셀에 어떻게 표현될지를 재계산하므로 화면이 깨지지 않음.
- 글꼴들
JPEG 이미지 형식
- 근처에 있는 픽셀들을 묶어, 비슷한 색들을 뭉뚱그리는 방식으로 이미지를 압축함.
- 저장할 때 압축률을 높이거나 재압축이 일어나게 될 경우, 색상 정보의 손실이 생김.
PNG 이미지 형식
- 이미지에 사용된 색상을 미리 정의해두고 이를 참조하는 팔레트 방식을 사용함.
- 색상 정보의 손실 없이 이미지 압축이 가능함.
GIF 형식의 이미지
- 이미지 내에 여러 프레임을 두어 이를 움직이게 만들 수 있음.
- 색상 정보를 손실 없이 저장하지만, 256개의 색상만 기억할 수 있는 팔레트 방식으로 제한됨.
컬러 스페이스 (color space)
- 컬러 시스템을 3차원으로 표현한 공간 개념
- RGB, HSV, YUV 등 색을 표현하는 다양한 방식
- 채널(channel): 컬러 스페이스를 구성하는 단일 축 ( RGB에서의 각각 R, G, B )

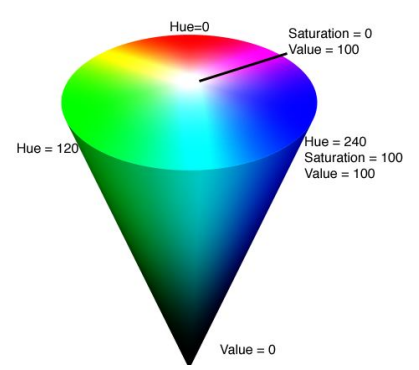
HSV (Hue: 색상, Saturation:채도, Value:명도)
이미지 데이터
- [ 가로, 세로, 채널 수 ] 형태의 배열
- 가로 x 세로 각 32픽셀에 RGB 세 가지 색상의 채널이 있다면, Numpy로 [32, 32, 3]차원의 배열을 생성하면 됨.
- 데이터 타입을 uint8(부호가 없는 8비트 정수)가 되어 0~255 사이의 값을 나타내도록 해야 함.
import numpy as np
from PIL import Image
data = np.zeros([32, 32, 3], dtype=np.uint8) # 모든 채널의 값이 0이기 때문에 검은색 이미지로 출력됨.
Image.fromarray(data, 'RGB') # fromarray()를 통해 배열을 바로 이미지 객체로 변환한 뒤 화면에 표시함.
data[:, :] = [255, 0, 0] # 모든 픽셀이 빨간색의 값을 가짐.
Image.fromarray(data, 'RGB')
-----------------------------------------
import os
# 이미지 파일 경로
image_path = os.getenv('HOME') + '/aiffel/python_image_proc/data/pillow_practice.png'
# 이미지 열기
img = Image.open(image_path)
img
# resize()를 이용하여 이미지 크기를 100 x 200으로 변경
resized_image = img.resize((100,200))
# crop()을 이용하여 특정 부분만 잘라냄.
box = (300, 100, 600, 400)
region = img.crop(box)
--------------------------------------
import os
import pickle
from PIL import Image
dir_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/cifar-100-python'
train_file_path = os.path.join(dir_path, 'train')
with open(train_file_path, 'rb') as f:
train = pickle.load(f, encoding='bytes')
# order 파라미터 값을 F로 주면 앞선 차원부터 데이터를 채움.
image_data = train[b'data'][0].reshape([32, 32, 3], order='F')
Image.fromarray(image_data)
# 이미지의 X축과 Y축을 바꿔줌.
여기에는 np.swapaxes(0, 1)
image_data = image_data.swapaxes(0, 1)
Image.fromarray(image_data)
OpenCV
- 오픈소스로 제공되는 컴퓨터 비전 라이브러리
- OpenCV에서는 RGB가 아닌, BGR 순서를 사용함.
import cv2 as cv
img_path = os.getenv('HOME')+'/aiffel/python_image_proc/data/cv_practice.png'
img = cv.imread(img_path) # 이미지를 읽어 들임.
# 원하는 색을 찾기 쉽도록 컬러스페이스를 BGR(RGB)에서 HSV로 변환함.
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
# 원하는 색의 최소와 최대를 설정함.
lower_blue = np.array([100,100,100])
upper_blue = np.array([130,255,255])
# HSV에서 원하는 색의 범위를 지정함.
mask = cv.inRange( hsv, lower_blue, upper_blue )
# 숫자로 파란색이라는 부분을 정의하고, 이 값들을 기준으로 이미지에서 마스크를 생성함.
# 마스크는 원하는 색을 떼어낼 수 있도록 하는 역할을 함.
# cv.inRange()는 기준들을 적용하여, 해당하는 픽셀에는 1, 그렇지 않은 픽셀에는 0을 찍어놓은 배열을 반환함.
# 이미지 두 장을 받아서 AND 비트 연산을 함.
res = cv.bitwise_and( img, img, mask=mask )
plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB))
plt.show()

plt.imshow(cv.cvtColor(mask, cv.COLOR_BGR2RGB))
plt.show()

plt.imshow(cv.cvtColor(res, cv.COLOR_BGR2RGB))
plt.show()

# 채널별 히스토그램을 생성함.
channel_histogram = cv.calcHist(images=[image],
channels=[i],
mask=None,
histSize=[4], # 히스토그램의 구간을 4개로 함.
ranges=[0, 256])
histogram = cv.normalize(histogram, histogram)
# 히스토그램 간 유사도를 계산함.
distance = cv.compareHist(H1 = target_histogram, H2 = histogram, method = cv.HISTCMP_CHISQR)
PNG (Portable Network Graphics) 파일
- 무손실 압축을 사용하여 이미지 손실이 없고, 고품질 이미지를 생성하여 이미지 편집에 많이 사용됨.
- 배경이 투명해서 배경 이미지 위에 png 파일을 얹어 두 이미지를 자연스럽게 합성시킬 수 있음.
랜드마크 (landmark)
- 눈, 코, 입, 귀와 같은 얼굴 각각의 위치들을 찾아내는 기술
- face landmark 데이터셋은 눈, 코, 입, 턱을 포함하고 있으며, bounding box로 잘라낸 얼굴 이미지를 이용함.
- 조금 더 큰 범위로 keypoint detection 이라고 부름.
이미지 읽기의 flag
- cv2.IMREAD_COLOR = 1: 이미지 파일을 Color로 읽어들임. (Default)
- cv2.IMREAD_GRAYSCALE = 0 : 이미지를 Grayscale로 읽어 들임. (이미지 처리시 중간단계로 많이 사용함.)
- cv2.IMREAD_UNCHANGED = -1 : 이미지 파일을 alpha channel까지 포함하여 읽어 들임.
dlib의 face detector
- HOG와 SVM을 사용해서 얼굴을 찾음.
- HOG (Histogram of Oriented Gradients): 이미지에서 색상의 변화량
- SVM (Support Vector Machine): 여러 이미지 벡터를 잘 구분짓는 방법
sliding window
- window를 이동해가며 확인하는 방법
- 큰 이미지의 작은 영역을 잘라 얼굴이 있는지 확인하고, 다시 작은 영역을 옆으로 옮겨 얼굴이 있는지 확인함.
이미지 피라미드
- upsampling 방법을 통해 이미지 크기를 키우는 것
- 이미지 피라미드에서 얼굴을 다시 검출하면 정확도가 올라감.
Object keypoint estimation 알고리즘
- 객체 내부의 점(point)을 찾는 기술
top-down : bounding box를 찾고, box 내부의 keypoint를 예측함.
bottom-up : 이미지 전체의 keypoint를 찾고, point 관계를 이용해 box를 생성함.
import cv2 # OpenCV라이브러리 → 컴퓨터 비전 관련 프로그래밍을 쉽게 할 수 있도록 도와주는 라이브러리
import dlib # 이미지 처리 및 기계 학습, 얼굴인식 등을 할 수 있는 라이브러리
my_image_path = 'aiffel/camera_sticker/images/image.png'
img_bgr = cv2.imread(my_image_path)
img_show = img_bgr.copy() # 출력용 이미지를 따로 보관
plt.imshow(img_bgr)
plt.show()
# matplotlib, dlib 등의 이미지 라이브러리는 모두 이미지 채널을 RGB(빨강, 녹색, 파랑) 순으로 사용
# opencv는 예외적으로 BGR(파랑, 녹색, 빨강)을 사용
# opencv에서 다룬 이미지를 다른 이미지 라이브러리를 활용하여 출력하려면 색깔 보정처리를 해줘야 함.
img_rgb = cv2.cvtColor( img_bgr, cv2.COLOR_BGR2RGB )
plt.imshow( img_rgb )
plt.show()
# 기본 얼굴 감지기
detector_hog = dlib.get_frontal_face_detector()
# 얼굴의 bounding box를 추출
dlib_rects = detector_hog( img_rgb, 1 ) # (이미지, 이미지 피라미드 수)
# 찾은 얼굴 영역의 좌표
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle( img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA )
# 시작점 좌표(l,t)와 종료점 좌표(r,b)로 직사각형을 그림
img_show_rgb = cv2.cvtColor( img_show, cv2.COLOR_BGR2RGB )
plt.imshow( img_show_rgb )
plt.show()
model_path = 'aiffel/camera_sticker/models/shape_predictor_68_face_landmarks.dat'
landmark_predictor = dlib.shape_predictor( model_path )
# dlib.rectangle: 내부를 예측하는 박스
# dlib.full_object_detection: 각 구성 요소와 이미지 상의 객체의 위치를 나타냄.
list_landmarks = []
for dlib_rect in dlib_rects:
# 모든 landmark의 위치정보를 points 변수에 저장함.
points = landmark_predictor( img_rgb, dlib_rect )
# 각각의 landmark 위치정보를 (x,y) 형태로 변환하여 리스트로 저장함.
list_points = list( map( lambda p: (p.x, p.y), points.parts())) # parts() 함수로 개별 위치에 접근
list_landmarks.append( list_points )
print(len(list_landmarks[0])) # 각 원소는 68개의 랜드마크 위치가 나열된 리스트임.
# 랜드마크를 영상에 출력
for landmark in list_landmarks:
for point in landmark:
cv2.circle( img_show, point, 2, (0, 255, 255), -1)
# img_show 이미지 위 각각의 point에 크기가 2이고 (0, 255, 255)색으로 내부가 채워진(-1) 원을 그림.
img_show_rgb = cv2.cvtColor( img_show, cv2.COLOR_BGR2RGB )
plt.imshow( img_show_rgb )
plt.show()
# zip() : 두 그룹의 데이터를 서로 엮어주는 함수
# dlib_rects : 얼굴 영역을 저장하고 있는 값
# list_landmarks : 68개의 랜드마크 값 저장 (이목구비 위치 (x,y) )
for dlib_rect, landmark in zip( dlib_rects, list_landmarks ):
print(landmark[30]) # 코의 index
x = landmark[30][0] # 이미지에서 코 부위의 x값
y = landmark[30][1] - dlib_rect.height() // 2
# 이미지에서 코 부위의 y값 - 얼굴 영역의 세로를 차지하는 픽셀의 수
w = h = dlib_rect.width() # 얼굴 영역의 가로를 차지하는 픽셀의 수
print (f'(x,y) : ({x},{y})')
print (f'(w,h) : ({w},{h})')
# 준비해 둔 스티커 이미지를 읽어서 적용
sticker_path = os.getenv('HOME') + '/aiffel/camera_sticker/images/king.png'
img_sticker = cv2.imread( sticker_path ) # image객체 행렬을 반환함.
img_sticker = cv2.resize( img_sticker, (w,h) ) # 스티커 이미지 조정
refined_x = x - w // 2
refined_y = y - h
# refined_x, refined_y값에서 스티커 이미지가 시작됨.
print (f'(x,y) : ({refined_x},{refined_y})') # 이미지의 범위를 초과하면 음수가 발생함.
# opencv는 음수 인덱스에 접근 불가하므로 스티커 이미지를 잘라줘야함.
# 음수값만큼 스티커 이미지를 자름.
if refined_x < 0:
img_sticker = img_sticker[ :, -refined_x: ]
refined_x = 0
# 스티커 이미지가 시작할 y좌표값 조정
if refined_y < 0:
img_sticker = img_sticker[ -refined_y:, : ]
refined_y = 0
print (f'(x,y) : ({refined_x},{refined_y})')
# sticker_area는 원본 이미지에서 스티커를 적용할 위치를 미리 잘라낸 이미지임.
sticker_area = img_show[ refined_y : refined_y + img_sticker.shape[0], refined_x : refined_x + img_sticker.shape[1]]
# 스티커 이미지에서 0이 나오는 부분은 이미지가 없는 부분임. -> sticker_area 적용
img_show[refined_y:refined_y+img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
= np.where( img_sticker==0, sticker_area, img_sticker ).astype(np.uint8)
# 얼굴 영역과 랜드마크를 미리 적용해놓은 img_show에 스티커 이미지를 덧붙인 이미지가 나옴.
plt.imshow( cv2.cvtColor( img_show, cv2.COLOR_BGR2RGB ))
plt.show()
# bounding box와 landmark를 제거하고 최종 결과만 출력
sticker_area = img_bgr[ refined_y : refined_y + img_sticker.shape[0], refined_x : refined_x + img_sticker.shape[1]]
# img_bgr은 rgb로만 적용해놓은 원본 이미지임.
img_bgr[refined_y : refined_y + img_sticker.shape[0], refined_x : refined_x + img_sticker.shape[1]] = np.where( img_sticker==0, sticker_area, img_sticker).astype(np.uint8)
plt.imshow( cv2.cvtColor( img_bgr, cv2.COLOR_BGR2RGB))
plt.show()